Conversational AI-powered IVAs are designed to create natural, human-like conversations between users and machines. Using Natural Language Understanding (NLU) engines enables machines to comprehend and interpret human language. These engines are a subset of natural language processing (NLP) and artificial intelligence (AI) systems and are designed to extract meaning and information from text or speech data. NLU engines play a crucial role in various applications, including chatbots, virtual assistants, sentiment analysis, language translation, and more.
The conversation flow with Kore.ai intelligent virtual assistants (IVAs) passes through various Natural Language Understanding (NLU) and Conversation Engines before the IVA decides its action and response.
This article provides an overview of the NLP flow within a Kore.ai intelligent virtual assistant and shows how you can leverage its features to build an efficient and accurate IVA.
The Kore.ai NLU Engines and When to Use Them
The Kore.ai Experience Optimization (XO) Platform employs a multi-engine approach to natural language, which combines the following three models for optimal outcomes:
- Fundamental Meaning (FM): A computational linguistics approach that is built on ChatScript. The model analyzes the structure of a user’s utterance to identify each word by meaning, position, conjugation, capitalization, plurality, and other factors;
- Machine Learning (ML): Kore.ai uses state-of-the-art NLP algorithms and models for machine learning to enable VAs to be trained and to gradually improve their intelligence;
- Knowledge Graph Engine (KG): The Knowledge Graph helps you turn your static FAQ text into an intelligent and personalized conversational experience.
With its three-fold approach, the Kore.ai XO Platform enables you to accelerate the Natural Language Understanding (NLU) performance of the virtual assistant and achieve optimal accuracy with relatively less training data. Kore.ai automatically enables the trained NLP capabilities to all built-in and custom IVAs, and powers the way they communicate, understand, and respond to a user request.
When do you use each engine? Each engine has its own settings and configurations. Our article on Optimizing NLP to Improve IVA Performance discusses each in more detail.
Machine Learning Engine
Machine Learning (ML) is the recommended engine for training a VA. The reason for this is its flexibility and auto-learn feature. Given a few examples, the engine learns and is capable of understanding similar new utterances. The training utterances need not be full sentences, as the ML can learn from phrases too.
If you have a large corpus (a structured set of machine-readable texts) for each intent that you are planning to implement, then use Machine Learning. If you don’t have a corpus it would be a good idea to develop one. In the long run, it is better to spend time building a large corpus and use ML rather than going for the other less time-consuming, easier options.
The way you define a large corpus could differ depending on the intents. For example, if the intentions are very different from each other and can be understood using their sample data like “Find Flight” or “Change Seat“, then a corpus of 200-300 for each intent is sufficient. However, if intents are closer to each other (and usually start with a similar utterance, such as “Change Seat” and “Change Flight”, then the corpus should be in the 1000s of phrases.
Similarly, if you are planning to use Deep Neural Networks, you need a higher number of samples for better predictions of both True Positives and True Negatives, as these networks are data-hungry. Learn more about the ML Engine.
Knowledge Graph Engine
If your intents are more query-like in nature than transactional tasks or if the content is in documents and you want the IVA to answer user queries from documents, then use Knowledge Collection. This engine can also be used to trigger dialog tasks in response to user queries thus incorporating other features available within the Kore.ai XO Platform.
If you have a lot of Intents and do not have time to prepare alternate utterances, but you are able to manually annotate some important terms, use Knowledge Collection. It is advisable to spend some time building a corpus and going for Machine Learning since annotation in the Knowledge Graph works in a similar way to ML’s auto-learning process. Learn more about the Knowledge Graph.
Fundamental Meaning Engine
If you have cases where users employ idiomatic sentences or command-like sentences or if you are not too strict about some false positives then use the Fundamental Meaning (FM) engine. Learn more about the FM Engine.
NLP Organization within the XO Platform
To get started optimizing your IVA’s NLP, you need to select the IVA you’re working with, then access Build > Natural Language. The NLP options are categorized under various headings for your convenience:
- Training – In the Training section, you can define how the NLP interpreter recognizes and responds to the user input for an IVA, and then train the interpreter to recognize the correct user intent.
- Thresholds & Configurations – In this section, you can define the recognition confidence levels required for minimum recognition actions, the confidence range for asking a user to choose from a list of possible matches, and a recognition confidence level for a positive match for the knowledge graph.
- Modify Advanced Settings like auto training settings for user utterances and negative intent patterns.
NLP Building Blocks
When a virtual assistant built on the Kore.ai XO Platform receives a user utterance, it is processed to identify the user intent, extract any additional information (entities), and then answer the user via a task execution. NLP is mostly concerned with the first two – intent detection and entity extraction.

Steps in a Conversation Flow
The Conversation Flow involves going through the following steps:
- NLP Analysis: The user utterance goes through a series of NLP engines for entity extraction and intent detection. (You can extend the out-of-the-box NLP functionality to use your own engine. You can install the Bot Kit SDK and easily integrate the virtual assistant with any 3rd party NLP engine. The output from the 3rd party NLP engine complements the outputs from Kore.ai thus adding to the efficiency and accuracy of the engine.)
The engines provided by the Kore.ai XO Platform are as follows:- Fundamental Meaning Engine which breaks up the utterances based on the grammar constructs;
- Machine Learning Engine which classifies individual words in the utterance, using an example-based, auto-learning training process;
- Knowledge Collection Engine which mostly deals with FAQ type user queries. It can also be configured to trigger tasks in response to the user query;
- Traits Engine which is a multiclass classifier and can identify multiple categories in user utterances thus aiding in refining user intent detection;
- Small Talk Engine which adds human flavor to the conversations;
- Ranking and Resolver to score the results from the above engines and rank them according to the set business rules, with the purpose of deciding on the winning intent.
- Task Execution: The winning intent along with the entities extracted then passes through the conversation engine for the actual task execution. This engine maintains the state or context of the conversation with information like user details, the previous intents requested by the user, and any other information as tagged by the business rules. This helps provide a near-human conversation experience. The conversation engine uses this state information along with the following conditions to accept or reject the intent identified by the NLU engines.
-
- Pre-conditions – if an intent has a set of predefined conditions configured and if any of these conditions are not satisfied the winning intent is then rejected. For example, a booking payment intent should have the payee details available.
- Negative patterns capture the presence of a pattern that should not identify a particular intent. For example “I lost my bag, how do I retrieve it” should, not assume that the user wants to be provided with information about baggage, and instead attempt to track their bag, based on the presence of the phrase “lost my bag”
- Event handling – events defined for a welcome message, sentiment analysis, etc.
- Interruptions handling: Other conditions such as Interruption settings (to handle situations where another intent is identified during the course of an ongoing task) or Sentiment Analysis settings (user sounds angry and hence should be transferred to an agent) are crucial for the action to be taken.
- Response Generation: A response is generated and presented to the user based on the channel of interaction. The response could be a success message, information as requested by the user, prompt for missing information or message concerning their transfer to a human agent.

NLP Training
In the previous section, we have seen the NLP process of the Kore.ai virtual assistant, but it needs some training on your part to ensure that the process proceeds as per your requirements. So, how do you train a fully functional IVA to achieve the best results? How do you make maximum use of the features above?
We will see some basic guidelines for NLP training in this section, before going into the details of each of the NLU engines.
The NLP Training Process
Morphology is the underlying principle behind NLP. Morphology is the study of words, how they are formed, and their relationship to other words in the same language. It analyzes the structure of words and parts of words, such as stems, root words, prefixes, and suffixes. Morphology also looks at parts of speech, intonation, and stress, and the ways the context can change a word’s pronunciation and meaning.
Based on this, a user utterance undergoes the following preprocessing before an attempt at entity extraction and intent detection:
- Tokenization – Splitting of utterances into sentences (Sentence tokenization) and Splitting of Sentence(s) into words. Kore.ai NLP uses TreeBank Tokenizer for English. Each language might have its own tokenizer
- toLower() – Convert all the text into lower (Not done for German, since the word meaning changes based on the case). This process is done only by ML and KG engines.
- StopWord removal – Each language has its own set of stop words that can be edited by the developer. Stop words are the words in a stop list which are filtered out (i.e. stopped) before or after processing of natural language data (text) because they are insignificant. This includes word like “a,” “the,” “is,” or “are”. Removes words that may not contribute to improving the learning. This process is done only in ML and KG engines. This setting is optional, but is disabled by default.
- Lemmatization or Stemming depending on the language
- Stemming – Retains the stem of the word like “Working”->” work”, “Running”->” Run”, “housing”->”hous”. It basically cuts the words. The output word may not be a valid language word
- Lemmatization – Converts the word to its base form using the dictionary. Like in earlier examples “Working”->” work”, “Running”->” Run” however, “housing”->” house”.
- N-grams – Helps in combining co-occurring words. For example, “New York City” and “Internet Explorer”. Each word has its own meaning. But when we take tri-gram in the first case and bi-gram in the second case, it actually results in a more meaningful word. N-grams also help in getting some context before or after a word.
Scoping
The first step in NLP training is to define the scope of the IVA, narrowing down the problem the Virtual Assistant will need to solve. This helps in configuring the various training nuances you will require. This involves brainstorming sessions with various stakeholders like SMEs/BAs, Conversation Experience Designers, IVA Developers, NLP Analysts/Data Engineers, NLP Trainers, and Testers.
The basic guidelines we suggest to keep in mind while scoping the IVA are the following:
- Start with a problem to solve – get a clear idea of what the IVA is supposed to accomplish. Talk to business analysts and IVA developers to understand the requirements and the actual functionality of the Virtual Assistant.
- Create a list of Intents – this will streamline the entire process
-
- For each intent, identify the key results that the IVA is aiming to accomplish;
- The focus should be on the needs of the user, not the platform requirements.
- Detail out example conversations – both user utterances and responses
-
- Create user personas and think about the conversations they might engage in with your IVA.
- Think through edge cases, follow-ups, and clarifying questions;
- You can leverage the Storyboard feature of the platform if it has not been already used for the IVA development phase.
- Brainstorm what an end user might ask as part of achieving their intent – these would be the alternate utterances for every intent. Try to also include idioms and slang.
Kore.ai NLP Version 3
Version 10.0 of the XO Platform includes a new version of the NLP Engine (Version 3) that comes with many advantages:
- Improved performance and accuracy of Traits Engine.
- Improved accuracy using network types like Transformer and KAEN models for the English Language.
- Improved accuracy using the Transformer model for other languages.
- Improved the security of NLP by addressing several security vulnerabilities.
- Improved performance by enabling LLM & Generative AI.
In addition, it allows you to explore the latest features like Zero-shot Model, Few-shot Model, and Intent Discovery.
Want to Learn More?
We're here to support your learning journey. Ready to take on bot building but not sure where to start? Learn conversational AI skills and get certified on the Kore.ai Experience Optimization (XO) Platform.
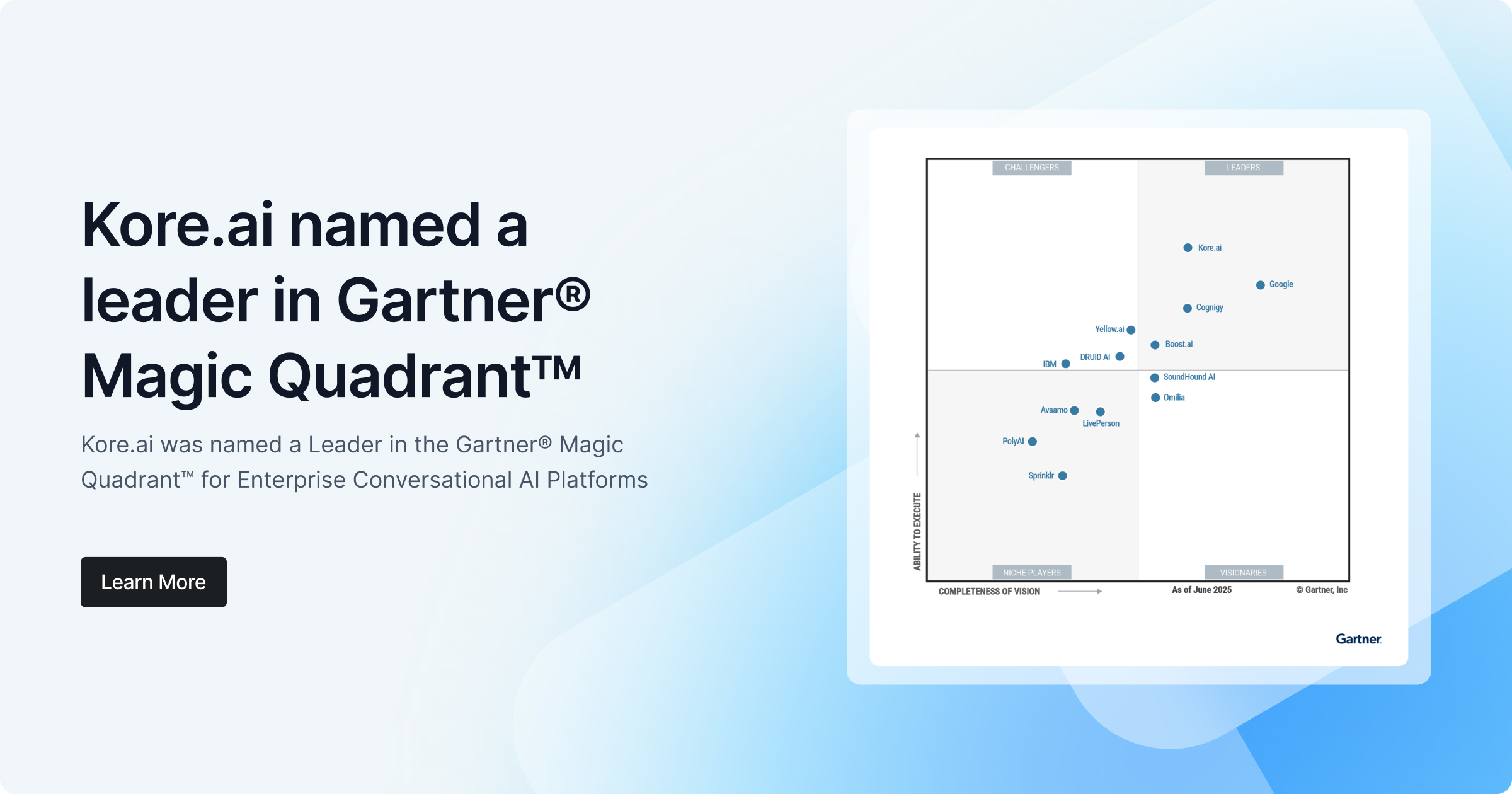
As a leader in conversational AI platforms and solutions, Kore.ai helps enterprises automate front and back-office business interactions to deliver extraordinary experiences for their customers, agents, and employees.





-1.jpg)




