The vocabulary in Generative AI and Conversational AI is evolving rapidly, introducing new terms that shape how we perceive and interact with these technologies.
This fast-paced innovation presents challenges, as keeping up with terminology becomes critical for clear and shared understanding.
Aligning these evolving terms with our shared mental models is essential for meaningful discussions and ensuring shared clarity in this dynamic field.
The phrases AI Agents, Autonomous Agents, Agentic Application, or what I refer to as Agentic X are all terms which are used interchangeably.
Introduction
Considering the evolution we have seen from basic prompt engineering to advanced AI Agents, the graph below illustrates key milestones:
Early language models and information retrieval systems formed the groundwork for prompt techniques. The 2015 introduction of attention mechanisms transformed language understanding, enabling greater controllability and context awareness.
In 2018-2019, advancements in fine-tuning and template-based generation marked significant progress, while reinforcement learning tackled challenges like exposure and text biases.
From 2020-2021, contextual prompting and transfer learning further refined these methods.
By 2022-2023, innovations like unsupervised pre-training and reward shaping enhanced prompt effectiveness.

Considering the image below, let's begin at number 10 and count back to 1.

Agentic X
The concept of "Agentic X" envisions agentic capabilities becoming integral to virtually all applications, embedding a layer of autonomy and intelligence.
These applications will possess the ability to manage complex tasks independently, breaking them into smaller, manageable components.
By leveraging such agency, systems can dynamically adapt to user needs and environments, delivering contextual solutions efficiently.
This paradigm shift will redefine how software interacts with users, emphasizing self-driven execution over static functionality.
Agentic Exploration
Web-Navigating AI Agents: Redefining Online Interactions and Shaping the Future of Autonomous Exploration.
Agentic exploration refers to the capacity of AI agents to autonomously navigate and interact with the digital world, particularly on the web.
Web-navigating AI agents are revolutionising online interactions by automating complex tasks such as information retrieval, data analysis, and even decision-making processes.
These agents can browse websites, extract relevant data, and execute actions based on predefined objectives, transforming how users engage with online content. By reshaping the way we interact with the web, these AI agents are paving the way for more personalised, efficient, and intelligent online experiences.
As they continue to evolve, web-navigating AI agents are poised to significantly impact the future of autonomous exploration, expanding the boundaries of what AI can achieve in the digital realm.
Agentic / Multi-Modal AI Agents
As agents grow in capability, they are also expanding into navigating by leveraging the image / visual capabilities of Language Models.
Firstly, language models with vision capabilities significantly enhance AI agents by incorporating an additional modality, enabling them to process and understand visual information alongside text.
I’ve often wondered about the most effective use-cases for multi-modal models, is applying them in agent applications that require visual input is a prime example.
Secondly, recent developments such as Apple’s Ferrit-UI, AppAgent v2 and the WebVoyager/LangChain implementation showcase how GUI elements can be mapped and defined using named bounding boxes, further advancing the integration of vision in agent-driven tasks.
AI Agents / Autonomous Agents
An AI Agent is a software program designed to autonomously perform tasks or make decisions based on available tools.
As illustrated below, these agents rely on one or more Large Language Models or Foundation Models to break down complex tasks into manageable sub-tasks.
These sub-tasks are organised into a sequence of actions that the agent can execute.
The agent also has access to a set of defined tools, each with a description to guide when and how to use them in sequence, addressing challenges and reaching a final conclusion.
Agentic Applications
Agentic applications refer to software systems that utilise autonomous AI agents to perform tasks, make decisions, and interact with their environment with minimal human intervention.
According to recent studies these applications leverage large language models (LLMs) to drive agent behaviours, enabling them to navigate complex tasks across various domains, including web navigation, data analysis, and task automation.
By integrating LLMs with other modalities like vision and reinforcement learning, agentic applications can dynamically adapt to changing inputs and goals, enhancing their problem-solving capabilities.
The study highlights how these agents can be evaluated for effectiveness in different scenarios, pushing the boundaries of what autonomous systems can achieve.
As agentic applications evolve, they hold the potential to revolutionise industries by automating intricate workflows and enabling new forms of intelligent interaction.
In-Context Learning / ICL
The underlying principle which enables RAG is In-Context Learning (ICL).
In-context learning refers to a large language model’s ability to adapt and generate relevant responses based on examples or information provided within the prompt itself, without requiring updates to the model’s parameters.
By including a few examples of the desired behaviour or context within the prompt, the model can infer patterns and apply them to new, similar tasks.
This approach leverages the model’s internal understanding to perform tasks like classification, translation, or text generation based solely on the context given in the prompt.
In-context learning is particularly useful for tasks where direct training on specific data isn’t feasible or where flexibility is required.
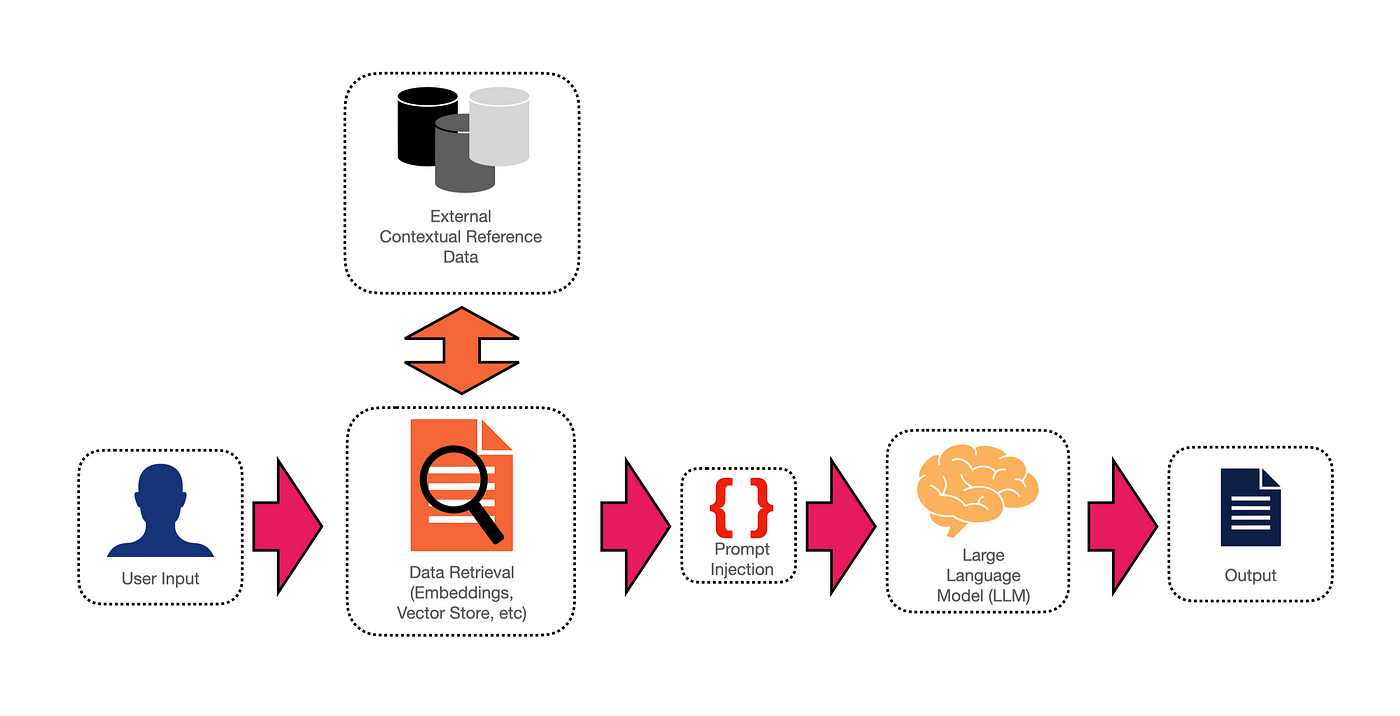
Retrieval Augmented Generation / RAG
Retrieval Augmented Generation (RAG) combines information retrieval and generative models.
By injecting the prompt with relevant and contextual supporting information, the LLM can generate telling and contextually accurate responses to user input.
Below is a complete workflow of how a RAG solution can be implemented. By making use of a vector store and semantic search, relevant and semantically accurate data can be retrieved.
Prompt Pipelines
In machine learning, a pipeline is an end-to-end construct that orchestrates the flow of events and data. It is initiated by a trigger, and based on specific events and parameters, it follows a sequence of steps to produce an output.
Similarly, in the context of prompt engineering, a prompt pipeline is often initiated by a user request. This request is directed to a specific prompt template.
Prompt pipelines can be viewed as an intelligent extension of prompt templates.
They enhance the predefined templates by populating variables or placeholders (a process known as prompt injection) with user queries and relevant information from a knowledge store.
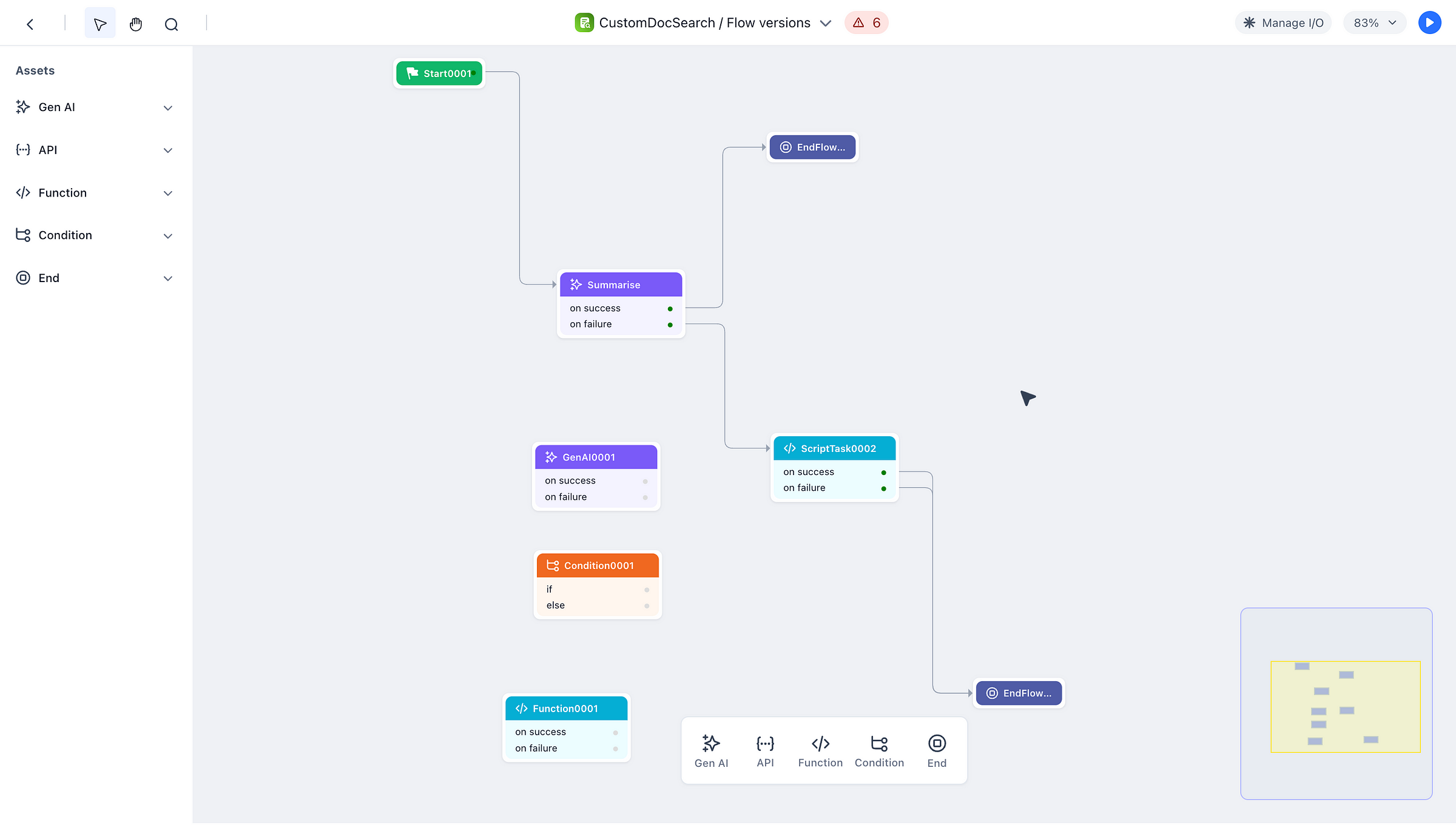
Below is an example from the GALE framework, on how a pipeline can be built in a no-code fashion.
Prompt Chaining
Prompt Chaining, also referred to as Large Language Model (LLM) Chaining, is the notion of creating a chain consisting of a series of model calls. This series of calls follow on each other with the output of one node in the chain serving as the input of the following.
Each chain node is intended to target small and well scoped sub-tasks, hence one or more LLMs is used to address multiple sequenced sub-components of a task.
In essence prompt chaining leverages a key principle in prompt engineering, known as chain of thought prompting.
The principle of Chain of Thought prompting is not only used in chaining, but also in Agents and Prompt Engineering.
Chain of thought prompting is the notion of decomposing a complex task into refined smaller tasks, building up to the final answer.
Prompt Composition
The next step is to develop a library of prompt templates that can be combined at runtime to create more advanced prompts. While prompt composition adds a level of flexibility and programmability, it also introduces significant complexity.
A contextual prompt can be constructed by combining different templates, each with placeholders for variable injection. This approach allows for parts of a prompt to be reused efficiently.
A contextual prompt is composed or constituted, with the different elements of the prompts having placeholders as templates.
Prompt Templates
A step up from static prompts is prompt templating.
In this approach, a static prompt is transformed into a template by replacing key values with placeholders.
These placeholders are then dynamically filled with application values or variables at runtime.
Some refer to templating as entity injection or prompt injection.
In the example template example below you can see the placeholders of
${EXAMPlES:question},
${EXAMPlES:answer} and
${QUESTIONS:question} and these placeholders are replaced with values at runtime.
Static Prompts
Generation is a core functionality of large language models (LLMs) that can be effectively utilised, with prompt engineering serving as the method through which data is presented, thereby influencing how the LLM processes and responds to it.
Text Generation Is A Meta Capability Of Large Language Models & Prompt Engineering Is Key To Unlocking It.
You cannot talk directly to a Generative Model, it is not a chatbot. You cannot explicitly request a generative model to do something.
But rather you need a vision of what you want to achieve and mimic the initiation of that vision. The process of mimicking is referred to as prompt design, prompt engineering or casting.
Prompts can employ zero-shot, one-shot, or few-shot learning approaches. The generative capabilities of LLMs are significantly enhanced when using one-shot or few-shot learning, where example data is included in the prompt.
A static prompt is simply plain text, without any templating, dynamic injection, or external input.
The following studies were used as a reference: