The paper on Self-Consistency Prompting was published 7 March 2023, as an improvement on Chain-Of-Thought Prompting. At the time it was certainly a novel advancement. However, so much has happened in the last few months.
Introduction
We have seen over the last few months a phenomenon referred to as Chain-Of-X, where a number of LLM interfaces have been premised on Chain-Of-Thought prompting.
These implementations have a number of similar characteristics; most notably the increase in complexity as the need for flexibility increases. The structure introduced is intended to assess and improve LLM input.
Data is also becoming increasingly important, with focus on In-Context Learning (ICL) and AI-Accelerated human annotation of data. The focus is shifting to data discovery, design, development and inspectability.
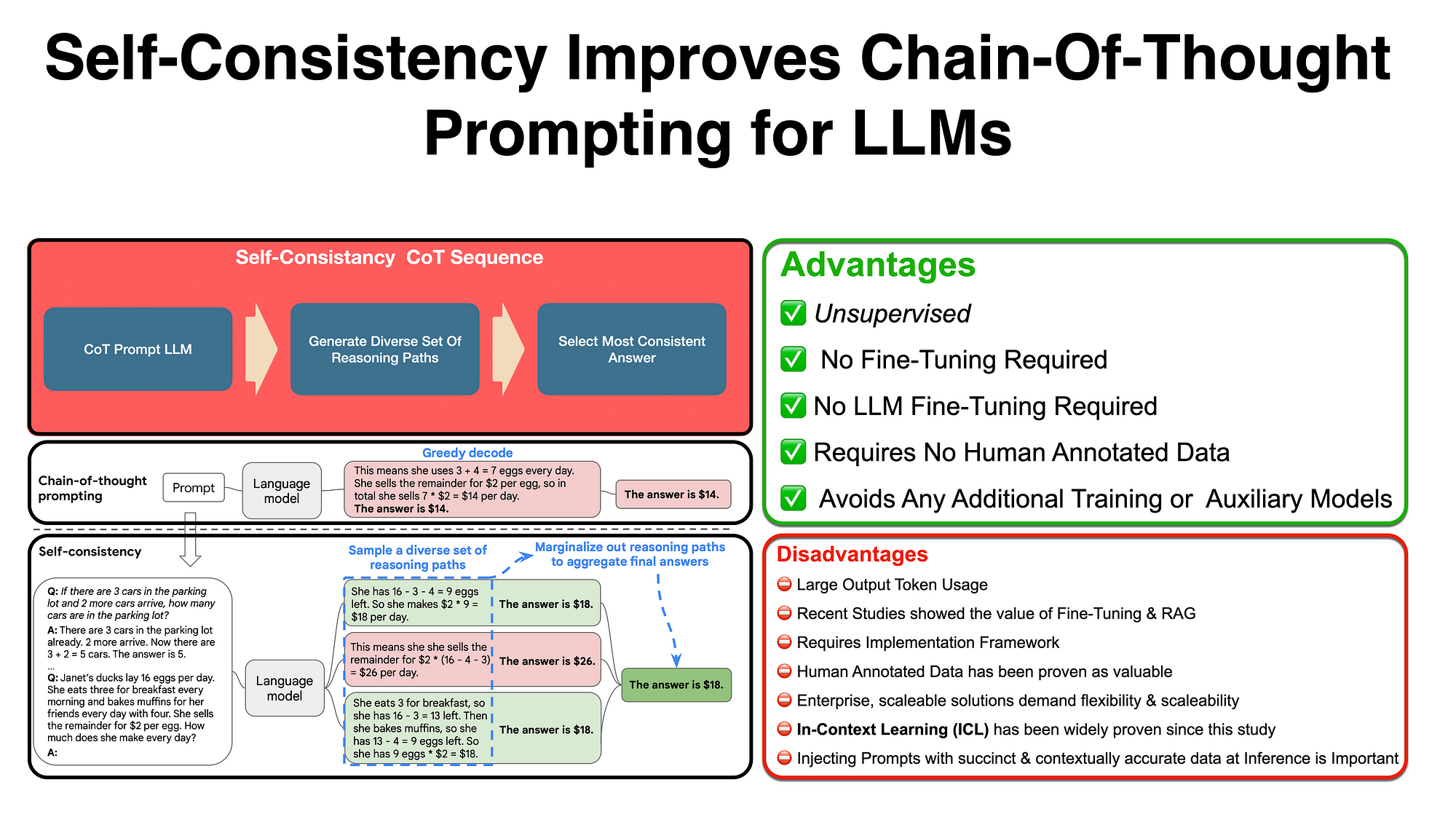
Back to Self-Consistency
The premise of self-consistency is leveraging the non-deterministic nature of LLMs, and that a LLM, when facing a reasoning problem typically generates multiple reasoning arguments.
The study describe Self-Consistency Prompting as a simple and effective way to improve accuracy in a range of arithmetic and common-sense reasoning tasks, across four large language models with varying scales.
The paper demonstrates clear accuracy gains, however, the process of sampling of diverse sets of reasoning paths and marginalising aberrations in reasoning to reach a aggregated final answer will demand the implementation of logic and a level of data processing.
Self-Consistency is Robust to Sampling Strategies and Scaling, Improves Robustness to Imperfect Prompts and works for Non-Natural-Language Reasoning Paths and Zero-shot CoT.
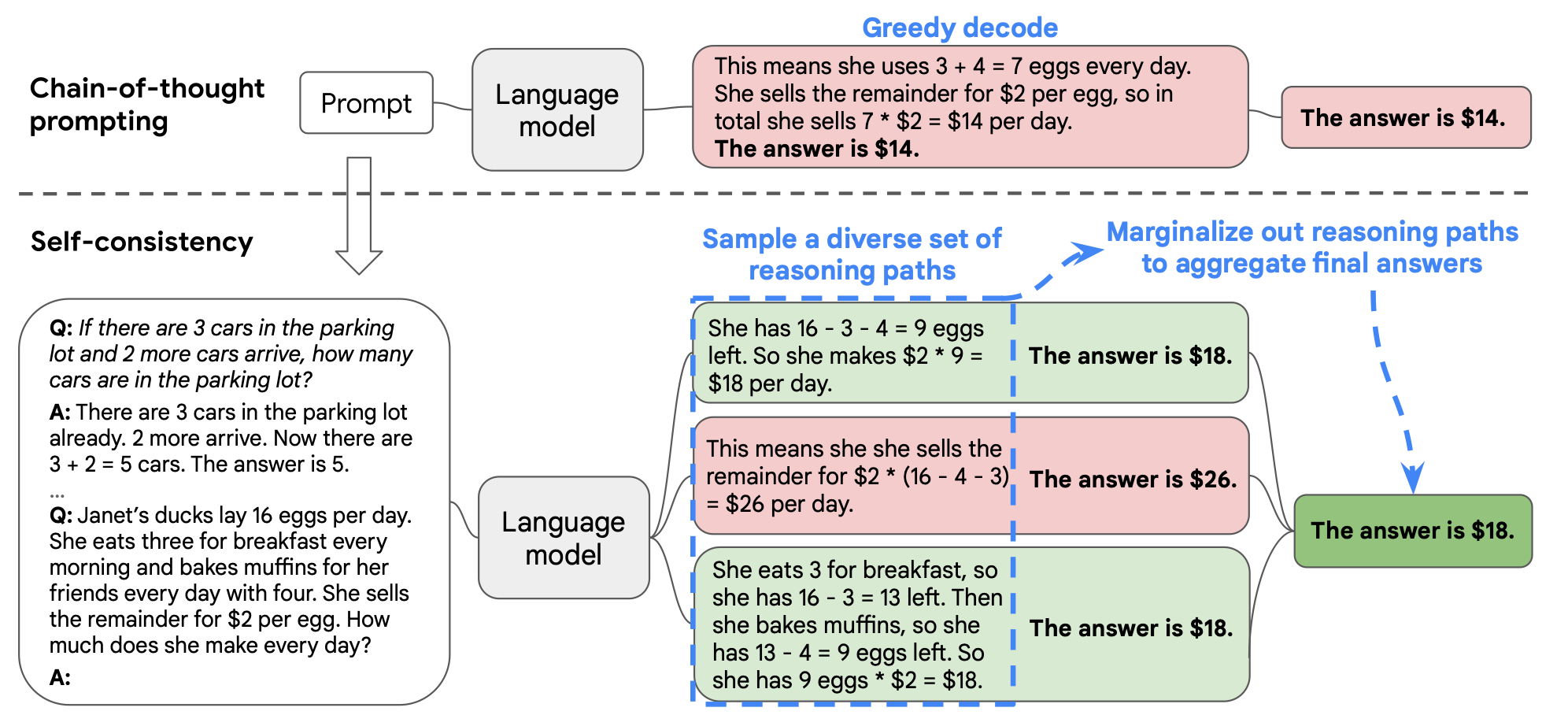
As seen above, the three steps involved in Self-Consistency Prompting;
Prompt a language model using chain-of-thought (CoT) prompting
Replace the “greedy decode” in CoT prompting by sampling from the language model’s decoder to generate a diverse set of reasoning paths; and
Marginalise out the reasoning paths and aggregate by choosing the most consistent answer in the final answer set.