Here I discuss the five emerging architectural principles for LLM implementations & how curation & enrichment of inference data will take centre stage.

Introduction
Considering most of the LLM-related studies which have been released in the last few months, there are a few trends which are emerging. These trends can be seen as general consensus on which research is setting in terms of how generative apps are most effective.
1. Complexity
Complexity is being introduced in the way inference data is processed and prepared, and delivered to the LLM. The general approach of decomposing a task into sub-tasks is becoming the de facto standard; while performing prompt engineering techniques like self-explaining, planning and other data related tasks.
Application based on LLMs are making use of prompt pipelines, agents, chaining and more.
2. LLM-Based Tasks
Some of the data and other outcome related tasks are offloaded to the LLMs. This is a sort of LLM orchestration where tasks which in the past might have been supervised by humans or managed via other processes, are given to LLMs to handle.
For instance, where data lacks, LLMs can be used to generate synthetic data,generating explanations, decomposition of tasks and planning. Contrastive chains, and more.
3. In-Context Learning (ICL)
A new study argues that Emergent Abilities are not hidden or unpublished model capabilities which are just waiting to be discovered, but rather new approaches of In-Context Learning which are being developed.
To successfully leverage in-context learning, highly contextual reference information needs to be delivered to the LLM at inference.
4. Human Feedback
Recent studies are starting to emphasise the importance of a data centric approach with making use of human inspected and labeled data. Especially with fine-tuning becoming more accessible a good data practice will become essential.
5. Inspectability & Observability
LLM-based implementations can widely be divided into two categories; gradient and non-gradient.
Data can be delivered to a LLM at two stages, during model training (gradient) or at inference time (gradient-free).
Model training creates, changes and adapts the underlying ML model. This model is also referred to as a model frozen in time with a definite time-stamp. This is generally an opaque process with limited inspectability and observability.
The reason why non-gradient approaches are favoured is the transparent and observable nature of this approach.
Inference is the moment the LLM is queried and where the model subsequently generates a response. This is also referred to as a gradient-free approach due to the fact that the underlying model is not trained or changed.
Recent research and studies have found that providing context at inference is of utmost importance and various methods are being followed to deliver highly contextual reference data with the prompt to negate hallucination. This is also referred to as prompt injection.
Context and conversational structure can be delivered via RAG, prompt pipelines, Autonomous Agents, Prompt Chaining and prompt engineering techniques.
Considering Random CoT
Considering the image below, multiple CoT responses are generated by the LLM together with self-evaluation. These responses are generated via natural language at inference.
The study states that LLM human-like self-evaluation enables the LLM to evaluate for itself the correctness of the generated CoT reasoning; and ascertain what is correct (highlighted in blue) or incorrect (highlighted in red).
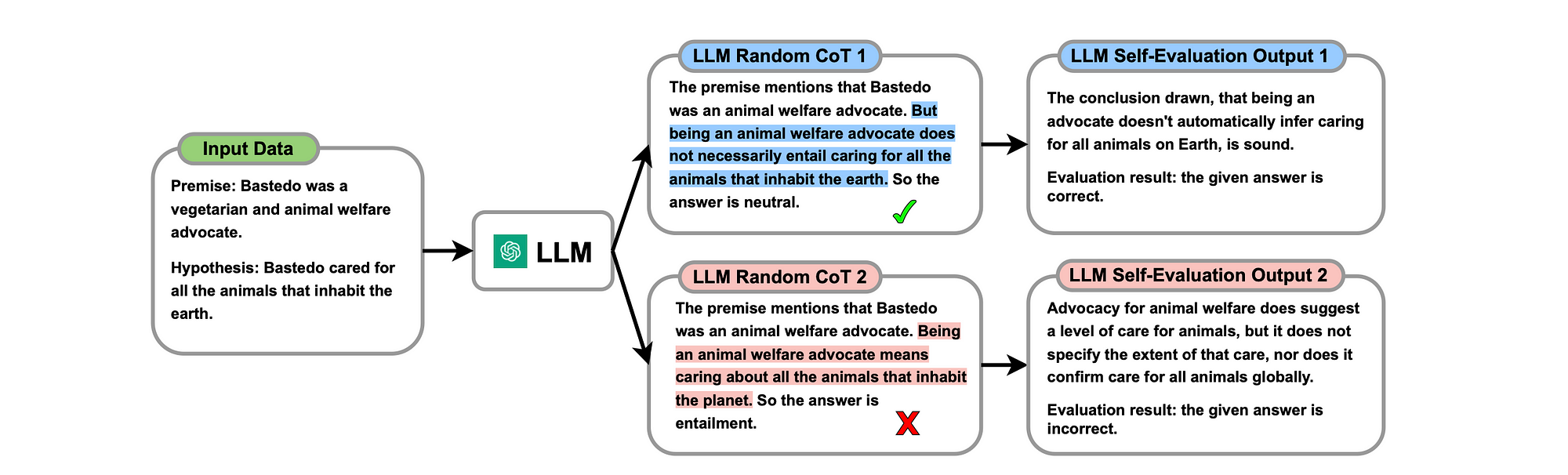
This concept again illustrates how the principles I described earlier in this article is applied to leverage LLMs for tasks to improve inference results.
Distilling Self-Evaluation Capability & Comprehensive Thinking
Considering the image below…
Step 1
Multiple CoTs are obtain from the LLM.
An unlabelled dataset is used, to devise a CoT prompt template describing how the task should be approached.
The prompt template contains examples for few-shot CoT. Following the CoT method, each example comprises of a triplet with:
- Example input
- Pseudo labels
- and user-provided rationale explaining the classifications.
Step 2
Obtain multiple self-evaluation outputs from the LLM.
Step 3
Train the SLM with multiple self-evaluation outputs, empowering the SLM to distinguish right from wrong.
Step 4
Train the SLM with multiple CoTs to give the SLM comprehensive reasoning capabilities.
Upon successfully incorporating the self-evaluation capability, the focus shifts to harnessing the various CoTs obtained from the LLM, aiming to train the SLM to internalise diverse reasoning chains.
This two-pronged training regimen ensures that the SLM is not merely parroting the capabilities but is rather steeped in introspective self-evaluation and a nuanced understanding of diverse reasoning, mirroring the advanced cognitive faculties of the LLM.
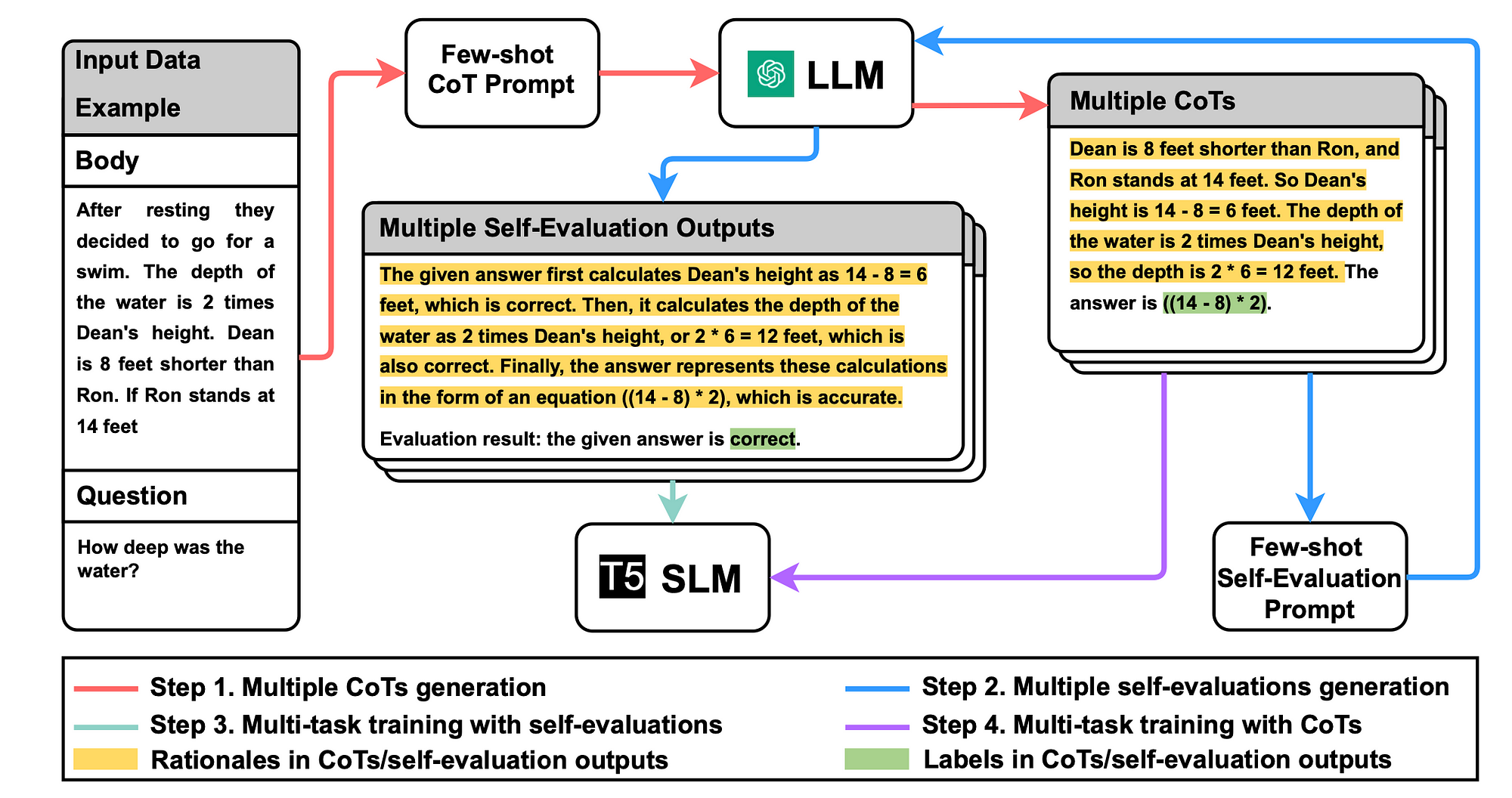
After generating diverse CoTs and their corresponding self-evaluation outputs using the LLM, the process begin to train the SLM.
The training methodology for SLMs first emphasises distilling self-evaluation capability to lay the foundation for reducing the impact of errors in CoTs on SLMs, followed by incorporating comprehensive reasoning capability through diverse CoTs distillation.
Distillation
This study illustrates an important method, called distillation…
LLM distillation includes various methods that leverage one or more large models to instruct a smaller model in accomplishing a specific task. In the context of this study, it’s referred to as a SLM (Small Language Model)…
In its most basic form, LLM distillation is initiated by instructing an LLM to assign labels to previously unlabelled data. This labeled dataset becomes the training set for a smaller model.
This approach can be used to leverage less capable, smaller, cheaper or less-capable models. The NLG prowess and basic logic of the model is leveraged, while the absence of a knowledge-intensive NLP (KI-NLP) component is lacking.
Data preparation is again key for this approach, pseudo-labels generated by the LLM can be used for to instruct smaller models, but preferably human- annotated labels should be used; or at least human supervision.
Previously published on Medium.










