Vector Embedding Free Retrieval-Augmented Generation
While Prompt-RAG does come with its limitations, it can effectively serve as an alternative to traditional vector embedding RAG methods in specific cases.
Prompt-RAG, akin to RAG, offers a vector database & embeddings free strategy to enhance Large Language Models (LLMs) for domain-specific applications.
Unlike RAG, which necessitates data chunking and vector embeddings for semantic search and retrieval, Prompt-RAG operates seamlessly without the need for such processes.
RAG
Retrieval-Augmented Generation (RAG) seamlessly merges generative capabilities with information retrieval techniques.
RAG strategically addresses the inherent limitations of generative models by combining the robustness of Large Language Models (LLMs) with real-time and contextual information.
The outcome is LLM-generated responses that exhibit natural and human-like qualities, while also being current, precise, and contextually aligned with the provided query.
Traditionally, RAG begins by converting input queries into vector embeddings.
These embeddings are then utilised to retrieve relevant data from a vectorised database. Subsequently, RAG’s generative component leverages the retrieved external data to craft responses that are contextually informed.
In this process, both the embedding and generative models play crucial roles, significantly influencing the effectiveness of RAG and directly impacting the retrieval process.
Prompt-RAG Steps
Prompt-RAG consists of three steps:
- Preprocessing,
- Heading Selection, and
- Retrieval-Augmented Generation.
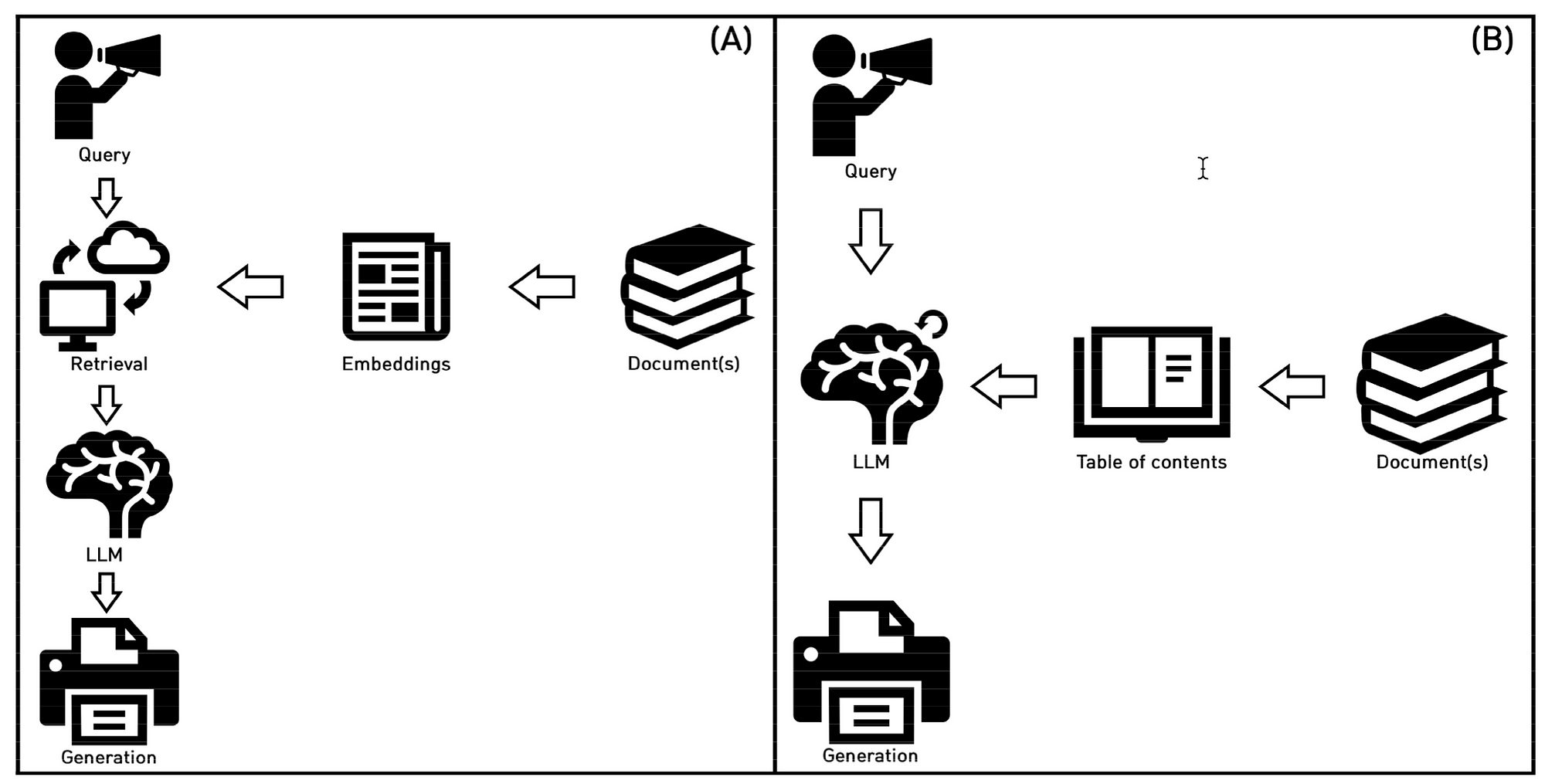
Preprocessing
In the initial phase, the creation of a Table of Contents (ToC) from the documents is paramount.
These documents are intricately linked to the specific domain that Prompt-RAG aims to address.
Ideally, a ToC should already be prepared by the document’s author.
However, if not available, it can be manually crafted. Alternatively, a Large Language Model (LLM) can be deployed to generate the ToC, particularly when the document structure is clearly defined.
The context-window size of the LLM significantly influences the size of both the ToC and the retrieved document sections.
To optimise token size, the document can be formatted by eliminating elements such as headers, footers, page numbers, etc.
This formatting ensures a streamlined and concise representation of the document content within the ToC and retrieved sections.
Heading Selection
The prompt includes the user query along with a Table of Contents (ToC), which is then provided to the Large Language Model (LLM).
The LLM is directed to identify the headings from the ToC that are most contextually pertinent to the query.
In some cases, multiple headings may be selected, and to further refine the selection, the text can be summarised. This summarisation process helps to narrow down the options, ensuring that the headings chosen are the most relevant to the user query.
The number of selected headings can be set in the prompt in advance depending on the budget and the context window size of the generative model for answer generation.
An important element is for the prompt to be optimised for accurate ToC retrieval and token use efficiency.
Prompt Injection
The next step involves retrieving portions of the document corresponding to the selected headings, which are then injected into the prompt as in-context references during inference.
It’s crucial that the size of the reference text injected into the prompt remains smaller than the context window size of the LLM.
To ensure compliance with this requirement, a Large Language Model (LLM) can be employed to summarise, truncate, or otherwise prune the retrieved “chunk.”
This process is necessary to tailor the reference text to fit within the constraints of the context window size and minimise token usage, thus optimising efficiency.
In cases where the selected headings are absent due to the query being a greeting or casual conversation, an alternative prompt without a reference section is passed to a GPT-3.5-turbo-based model, in order to reduce token usage and save on expenses.
The prompts for answer generation are shown below:
You are a chatbot based on a book called {Book Name}.
Here is a record of previous conversations:
{history}
Reference: {context}
Question: {question}
Use the reference to answer the question.
The reference above is only fractions of '<>'.
Be informative, gentle, and formal.
If you can't answer the question with the reference, just say like
'I couldn't find the right answer this time'.
Answer in {Language of Choice}:
Below the prompt template without selected headings for casual queries…
You are a chatbot based on a book called {Book Name}.
Here is a record of previous conversation for your smooth chats.:
{history}
Question: {question}
Answer the question.
Be informative, gentle, and formal.
Answer in {Language of Choice}:”
In Conclusion
The significance of the Prompt-RAG study is undeniable, even when Prompt-RAG is not employed independently. There are situations where Prompt-RAG can serve as a component within a larger implementation framework.
There exists a perpetual balance between optimizing and utilizing prompt engineering through innovative methods versus constructing a more intricate data management framework around an application. Typically, as implementations expand in both usage and complexity, the latter approach tends to prevail.
However, it’s essential to acknowledge that Prompt-RAG requires an application framework to oversee data flow, validate input and output, and conduct necessary data manipulation.
Traditional RAG disadvantages:
- Optimising document chunk size and managing overlaps can be a challenge.
- Updating chunks and embeddings as data changes to maintain relevance.
- Not optimised for minority language implementations
- Additional cost of running embeddings
- Cumbersome for smaller implementations
- Technically more demanding
Traditional RAG advantages compared to Prompt-RAG:
- Scales well
- More Data Centric Approach
- Bulk Data Discovery and data development will remain important for enterprise implementations.
- Semantic clustering is an important aspect of data discovery in general, and a good first-step into implementing RAG.
Prompt-RAG Advantages:
- Well suited for smaller, less technical implementations and minority languages.
- Ideal for a very niche requirement and implementation
- In the case of a chatbot, certain intents can be routed to a Prompt-RAG implementation
- Simplification
- Can serve as a first foray into full RAG implementations
- Non-gradient approach
- Inspectability and Observability
- A data discovery & data design tool aimed at optimising Prompt-RAG can add significant value.
Prompt-RAG Disadvantages:
- Data design is still required.
- Context window size is an impediment.
- Token usage and cost will be higher; this needs to be compared to embedding model token cost.
- Scaling and introducing complexity will demand a technical framework.
- Dependant on LLM inference latency and token usage cost.
- Content Structure needs to be created. The study largely focusses on documents which already has a Table of Contents.
Find the study here.










