And I’m curious to know if anyone has innovative approaches to using long context windows efficiently?
Long Context Windows are not replacing RAG, and I say this for a number of reasons.
- Large or Long Context Windows (LCWs) and RAG are two different use-cases.
- LCWs will be used in a once-off single prompt scenario, where multiple questions are asked off the long content submitted in a single prompt. Below is an example of such a prompt by Anthropic.
our task is to generate multiple choice questions based on content from the following document:
<document>
</document>
Here are some example multiple choice questions and answers based on other parts of the text:
<examples>
Q1: [Example question 1, created from information within the document]
A. [Answer option A]
B. [Answer option B]
C. [Answer option C]
D. [Answer option D]
Answer: [Correct answer letter]
Q2: [Example question 2, created from information within the document]
A. [Answer option A]
B. [Answer option B]
C. [Answer option C]
D. [Answer option D]
Answer: [Correct answer letter]
</examples>
Instructions:
1. Generate 5 multiple choice questions based on the provided text.
2. Each question should have 4 answer options (A, B, C, D).
3. Indicate the correct answer for each question.
4. Make sure the questions are relevant to the text and the answer options are all plausible.
3. LCWs will mainly be used by a single user in a once-off scenario. For large high volume architectures, it is not feasible to send such large swaths of data for each and every inference.
4. Inference cost will be extremely high due to the large number of tokens used for each inference.
RAG allows for a highly inspectable, observable and manageable solution which is a non-gradient approach. While optimising inference time, and leveraging LLMs unique ability of in-context learning.
5. An approach solely based on LCW is not optimised for speed considering inference wait time, and the sheer amount of data sent with each query.
6. Highly scaleable and optimised solutions will need a level of resilience which a LCW approach will not solve for due to it’s lack of granularity.
7. Just imagine how hard it will be to optimise a solution if a LCW approach is followed instead of RAG. The LLM is in essence a black box and the methods of accessing different sections of long context is opaque.
8. Large Language Models (LLMs) excel at In-Context Learning (ICL) and ICL is especially well leveraged by providing the LLM with just the right context for each inference.
9. A recent study called “Lost in the middle” proved how facts at the beginning and end of a long context submission document receives more coverage than documents at the end.
RAG is a step towards reaching LLM independence.
10. For a scaleable enterprise grade approach to Generative AI, data discovery is of utmost importance, together with data design.
Part of this process includes performing due diligence in terms of data privacy and anonymisation.
Discovering data with strong signals in terms of use-cases and customer intent lends itself to a natural and logical next step of chunking that data into highly contextual pieces of text to inject at inference.
11. RAG allows for highly inspectable, observable and manageable solutions which is a non-gradient approach. While optimising inference time, and leveraging LLMs unique ability of in-context learning.
12. RAG is a step towards reaching LLM independence. Research has shown that LLMs deemed inferior excel when provided with an in-context reference. RAG is largely LLM independent and by using a LCW approach, LLM independence will surely not be reached.
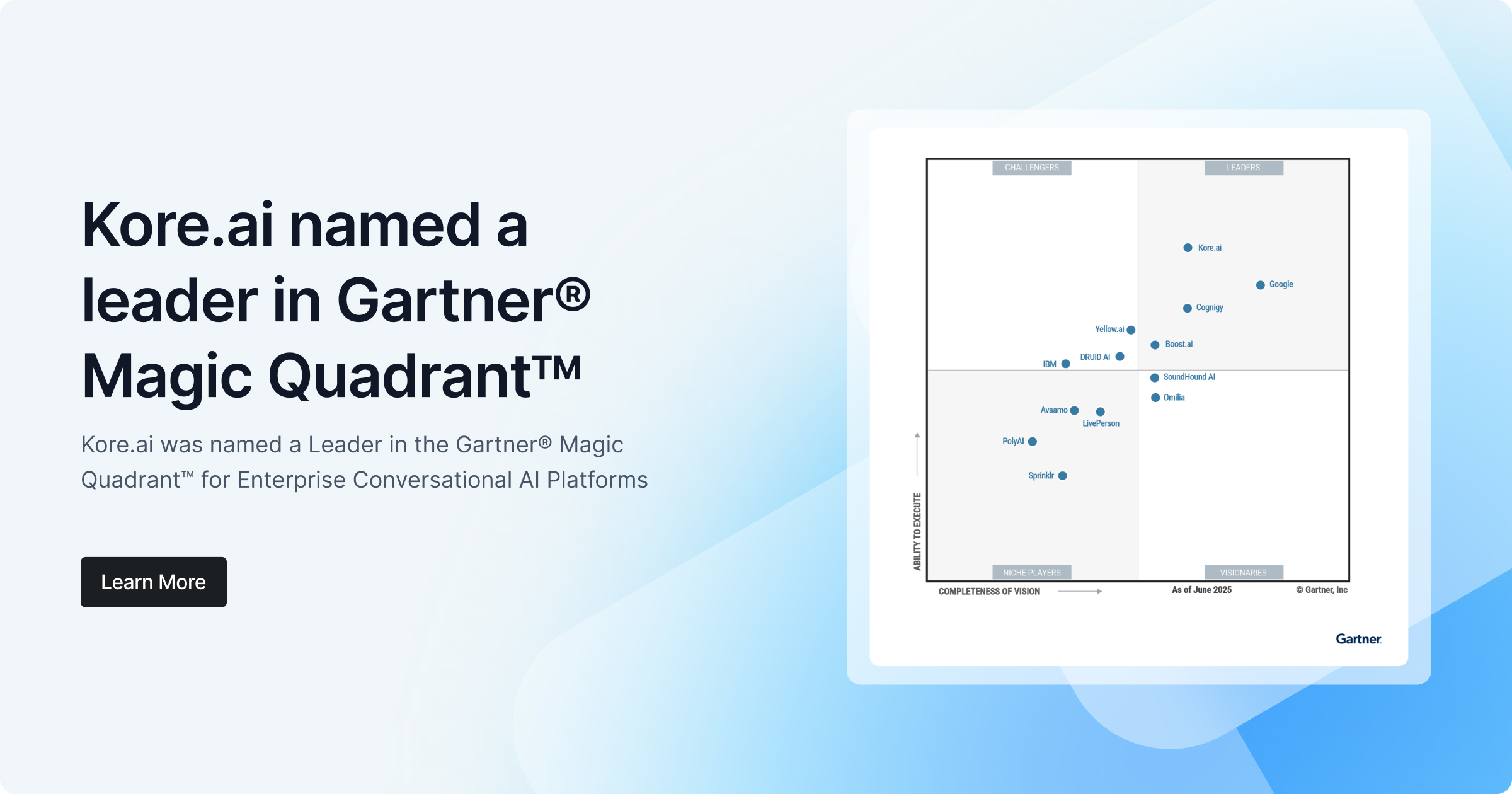
Tokens In Context
In order to put token use in context, below is the OpenAI tokenised calculator. The calculator converts text into tokens and can be used to calculate costs in terms of the size of the inference input and output.
Source
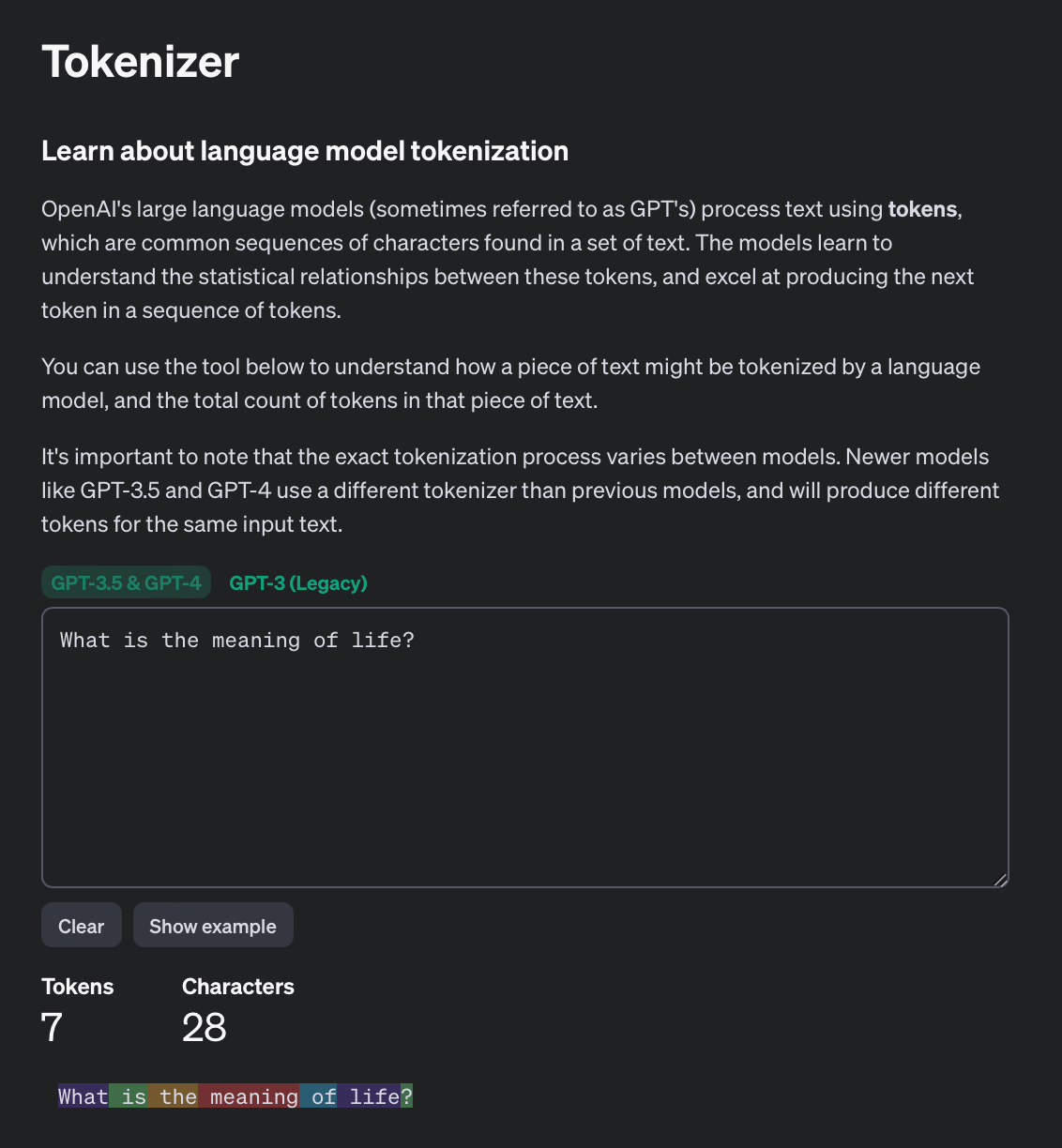
The table below shows the context window of a number of Anthropic and OpenAI models, with their respective pricing per 1 million tokens.
The graph below shows the number of tokens per second generated by the model. This is a good indication of the models’ inference time. It takes more than one second to generate one sentence.
In-Context Learning
A recent study has shown that LLMs in fact do not possess emergent capabilities, and what as deemed in the past as emergent capabilities is in fact the ability of LLMs to leverage in-context learning (ICL).
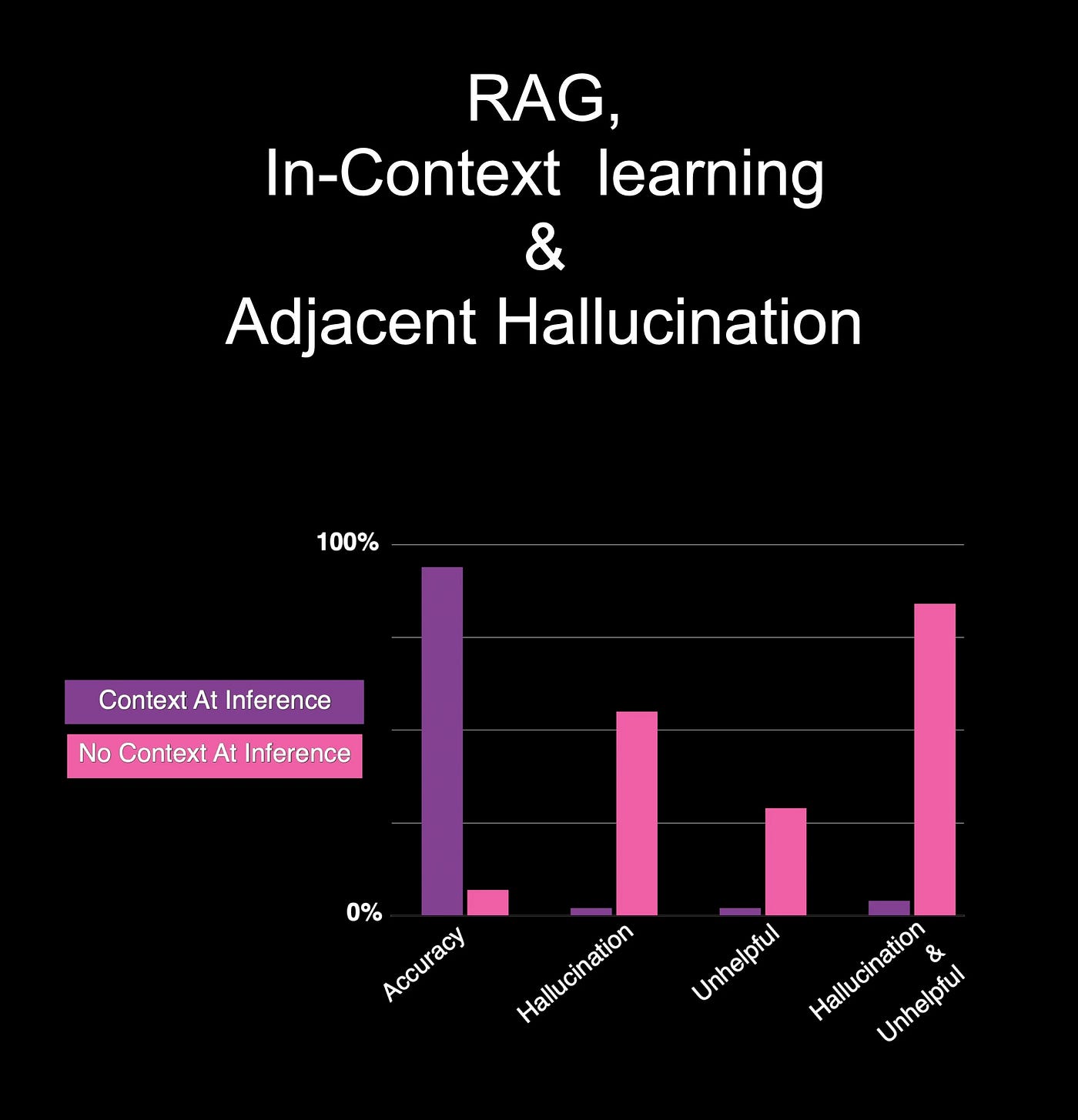
ICL leverages the LLM abilities of logic and common-sense reasoning, natural language generation, language understanding and contextual dialog management.
With the exception of not heavily relying on the knowledge intensive nature of LLMs.
Considering the graph above, the stark contrast is illustrated when context is present and absent. The categories the study considered was accuracy, hallucination, helpfulness and helpfulness combined with hallucination.
Lost In The Middle
A recent study examined the performance of LLMs on two tasks:
- One involving the identification of relevant information within input contexts.
- A second involving multi-document question answering and key-value retrieval.
The study found that LLMs perform better when the relevant information is located at the beginning or end of the input context.
However, when relevant context is in the middle of longer contexts, the retrieval performance is degraded considerably. This is also the case for models specifically designed for long contexts.
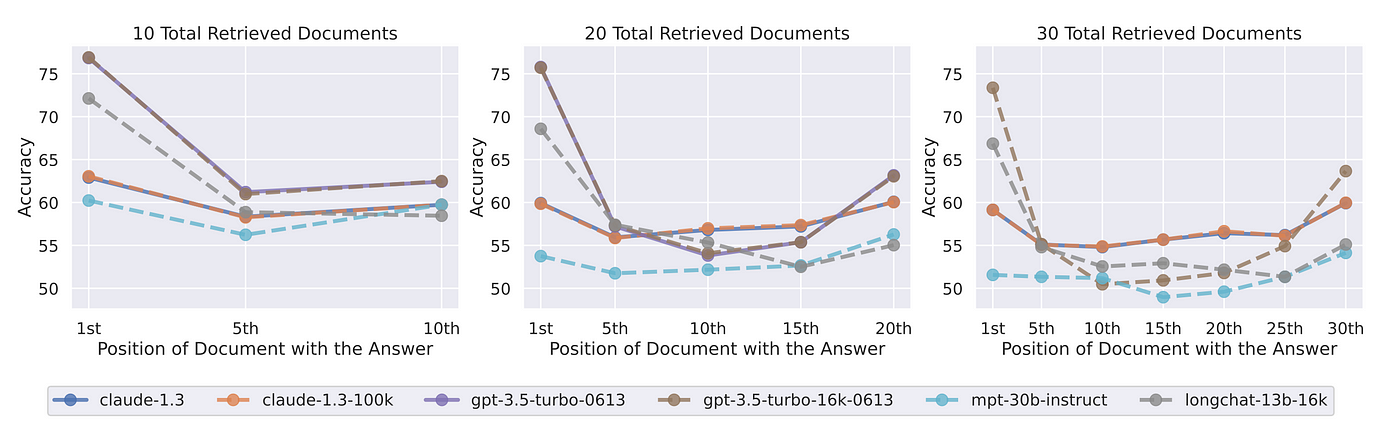
Extended-context models are not necessarily better at using input context. Source
Conclusion
In conclusion, there is significant value in understanding semantic similarity in any organisations data, knowing what conversations customers want to have, and optimising the data injected at inference.