Introduction
This study surfaces a very insightful and comprehensive taxonomy for improving LLM output. The taxonomy includes wide ranging elements, which can be used in isolation, or an approach can be multifaceted.
There is no single correct way to refine and correct LLM output; here are some key considerations:
- The availability of annotated data and people to perform annotation.
- The extent to which a data productivity suite is available to accelerate data discovery and annotation.
- The level to which different LLMs are available to orchestrate the process of critique and refinement.
- Access to people, technology and processes for refinement approaches like in-context learning (RAG), RLHF, Supervision, etc.
- If correction will be performed during or after inference.
- The number of accessible LLMs, token usage considerations, inference latency, etc.
LLM Structure
When building Gen-Apps two approaches are emerging…
The first approach is where the LLM-itself is leveraged as much as possible; hence the reliance on external data, frameworks and models are avoided.
Here the idea is to be resource efficient and leverage the LLM as much as possible. Negatives here are the inability to scale, difficulty when adding complexity, inspectability and observability.
The second approach is where a framework is at the centre, and not the LLM. The LLM is treated as a utility and the heavy lifting is offloaded as much as possible to an external framework; often human annotated data is used to improve accuracy and in-context learning.
Emerging LLM Techniques
The arrival of LLMs have seen the emergence of a number of classes of LLM related techniques. These techniques and classes most often did not exist in its current form a few months ago.
Amongst others, these emerging classes or techniques include, RAG, In-Context Learning, Prompt Pipelines or runnables, autonomous agents, prompt chaining and also self-correction.
The dangers of LLMs include hallucination, unfaithful reasoning, and toxic content.
One approach to solve for this is self-correction.
Self correction can be performed by an LLM; the same LLM can be used to check and verify its outputs. Or an external LLM can be utilised for correction.
Self-Correction is one of the emerging classes of LLM related techniques.
A prevailing strategy to rectify these undesired behaviours of LLMs is learning from feedback. — Source
Self-Correction
The two extremes of the self-correction spectrum has 100% human involvement at the one end, and 100% model involvement at the other hand.
The optimal solution lies somewhere in the middle where an approach is followed of AI augmented / AI accelerated humans by making use of a latent space / data productivity suite.
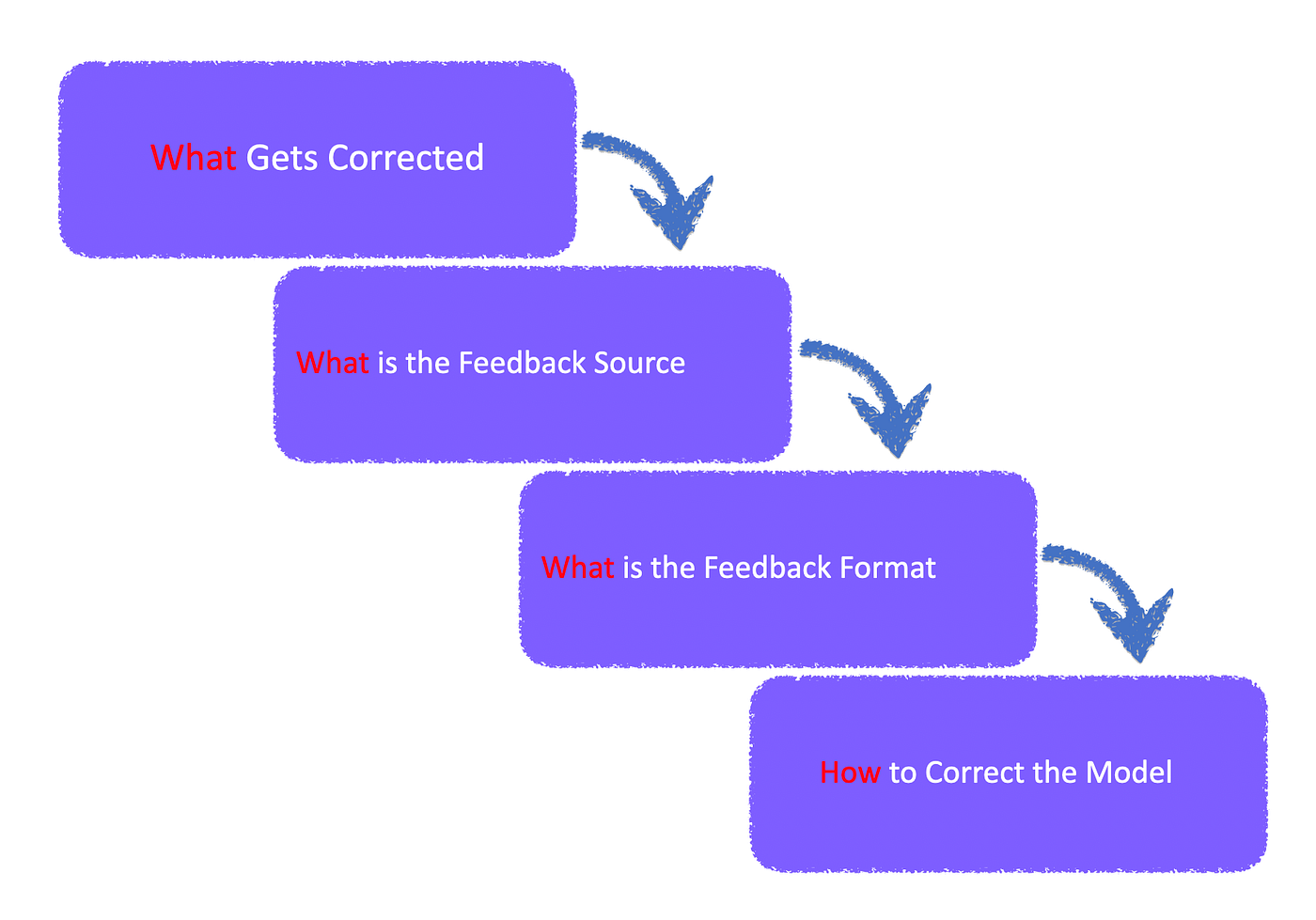
Considering the image above, four questions need to be answered.
These questions involve what needs to be corrected. A process is required to determine what data or output is incorrect and required correction.
The source of the feedback needs to be established together with the format of the feedback.
And lastly how to correct the model; the method of delivery of the feedback.
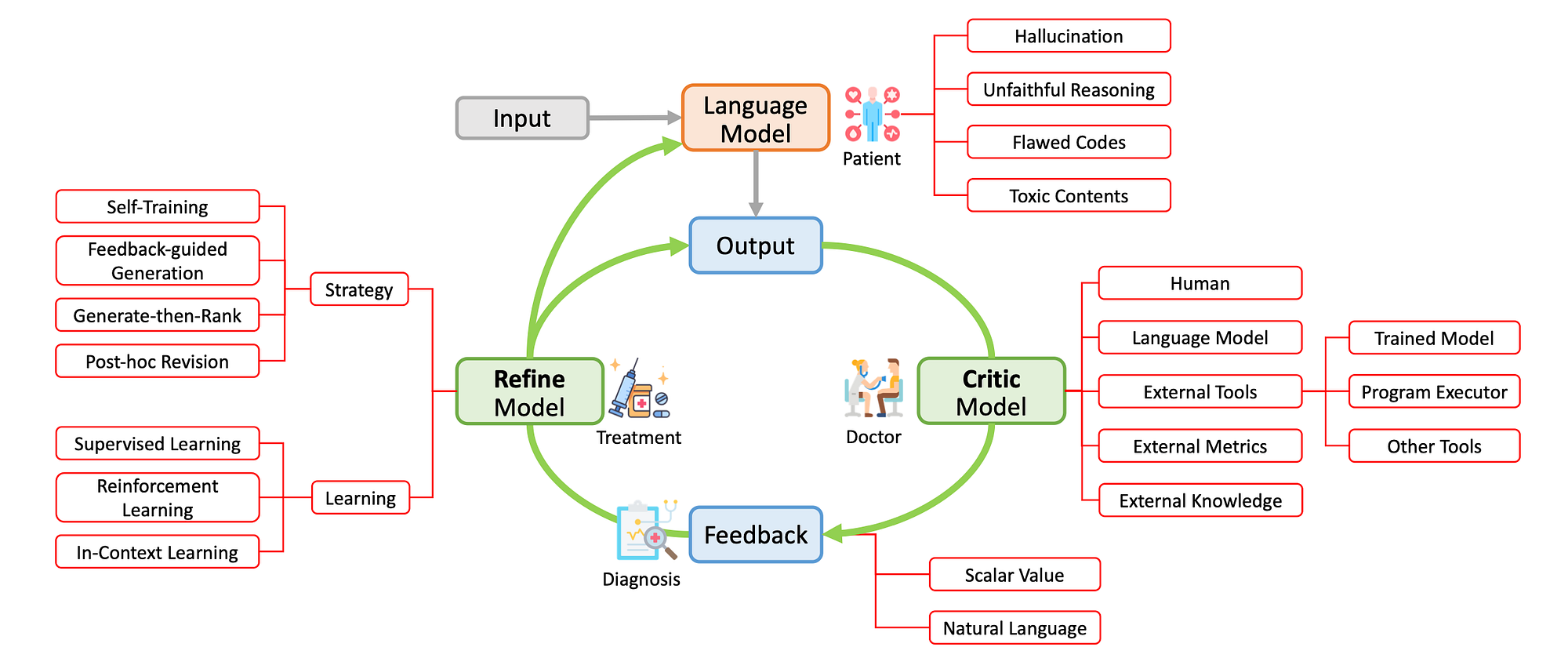
The image above shows a conceptual taxonomy for self-correcting LLMs, with automated feedback.
The Language Model which performs a specific task by mapping an input text to an output text.
The Critic Model analyses the output and provides feedback.
And the Refine Model provides treatment to either the output or the language model.
Existing works are taxonomised using this conceptualisation along five key aspects: the problem to be corrected, the source and format of the feedback, and the strategy and learning method of the refine model.
The What & How
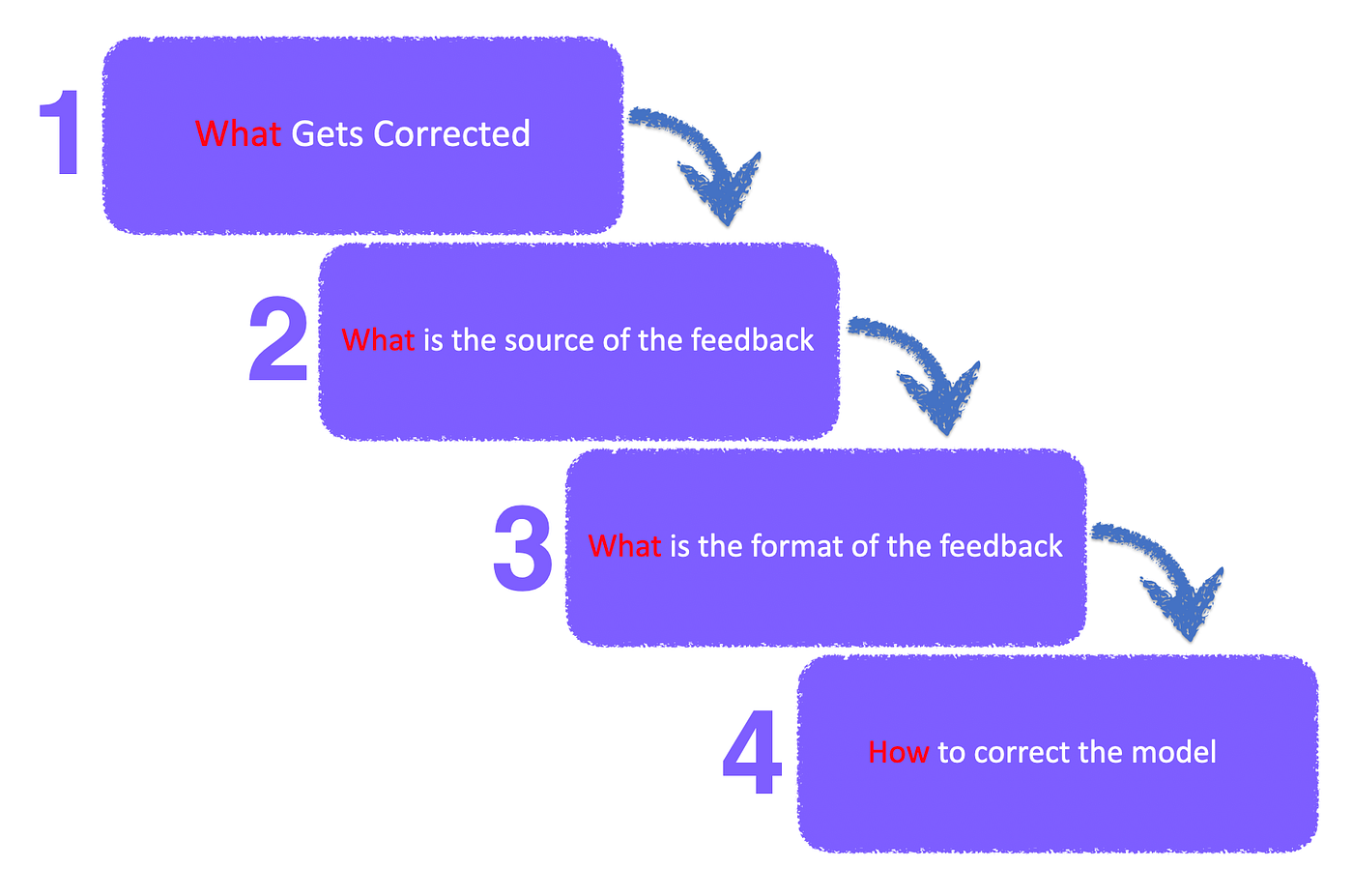
What Gets Corrected
- Hallucination,
- Unfaithful Reasoning,
- Toxic, Biased, and Harmful Content
- Flawed Code
From which Feedback Source
- Self-Feedback; the LLM itself can be utilised as a feedback provider.
- External Feedback; other trained models, external tools, external knowledge sources, external evaluation metrics, etc.
In What Format
The data format can include natural language, unstructured data, scalar data and more.
How to Correct
Training-time Correction. The ideal scenario is to rectify a flawed model during training, prior to its deployment for use.
Human feedback is typically used for training-time correction, as exemplified by the widely adopted RLHF approach.
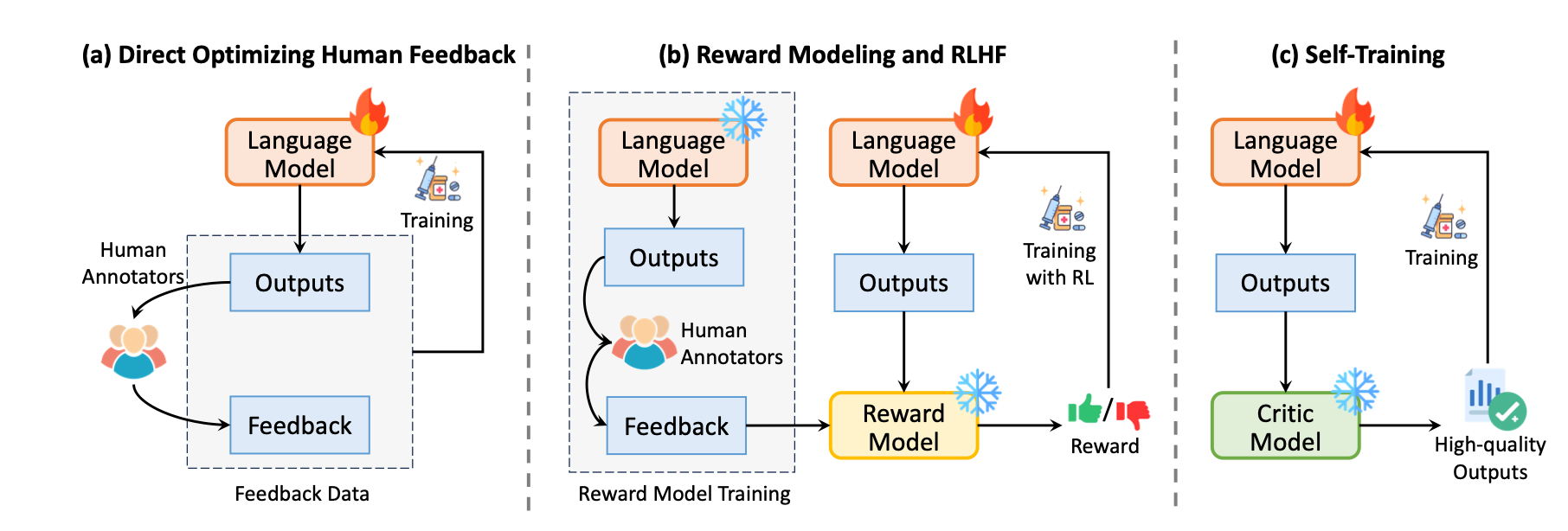
The image above shows three typical strategies of training-time correction.
a. Direct optimisation with human feedback,
b. Training a reward model that approximates human feedback,
c. Self-training with automated feedback.
Generation-time Correction. This strategy utilises automated feedback to guide the language model during generation
post-hoc correction involves refining the model output after it has been generated, without updating the model parameters.
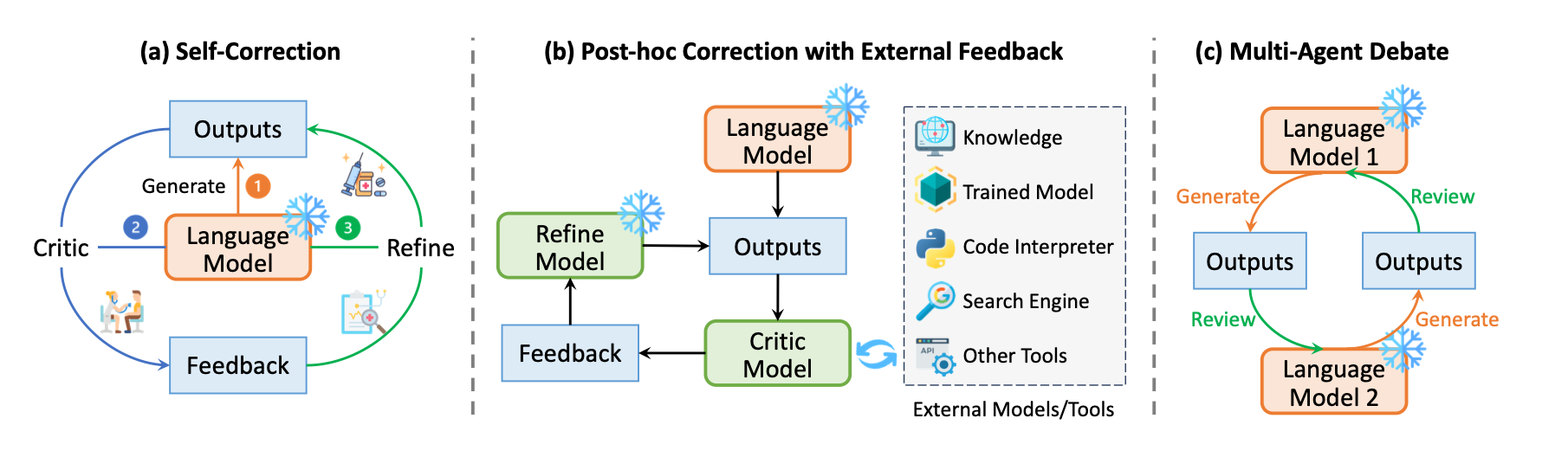
Three typical strategies of post-hoc correction:
a. Self-correction
b. Correction with external feedback
c. multi-agent debate
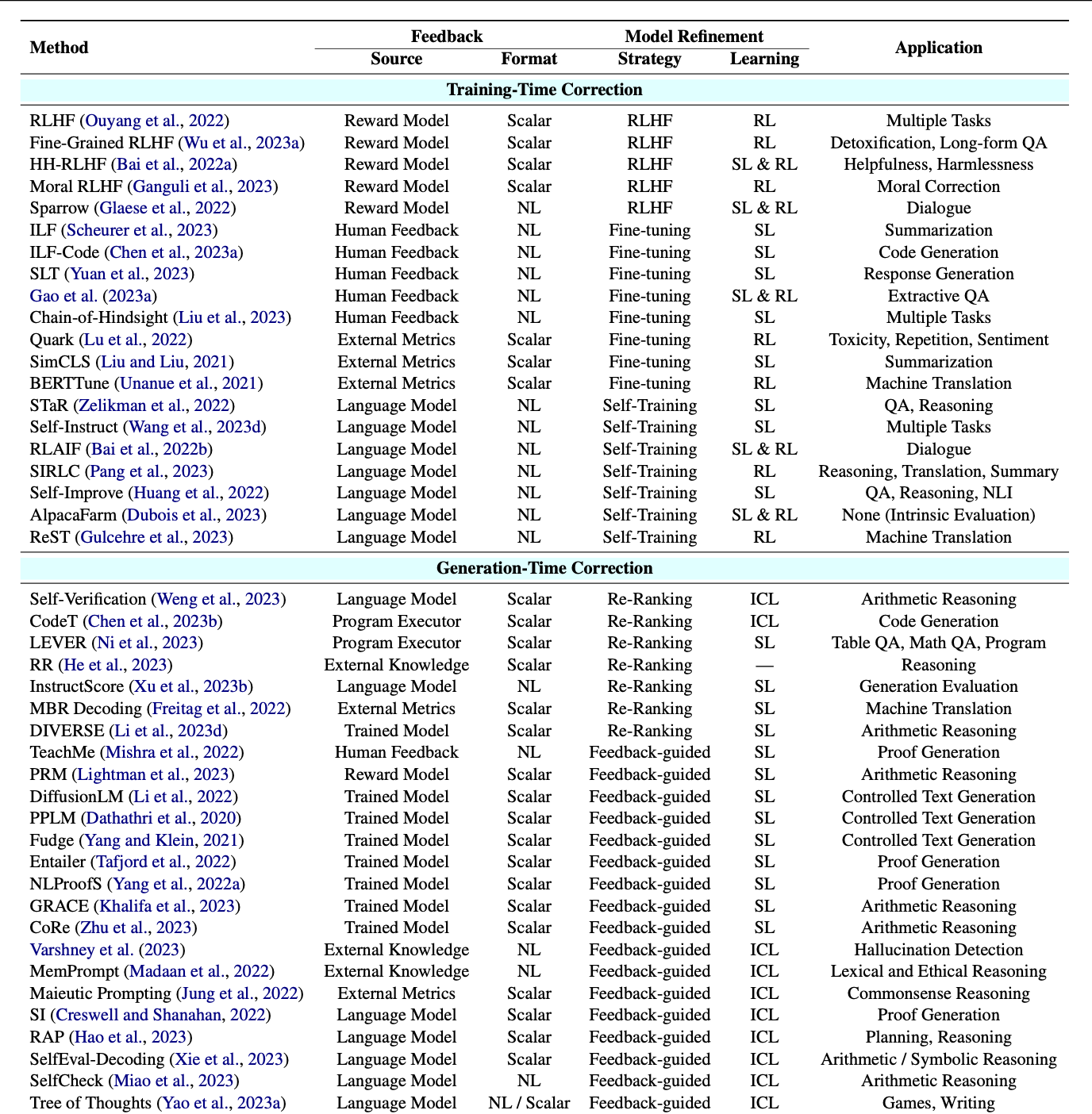
Source
Considering the image above, an invaluable list of resources and approaches to LLM correction is given. The list is split between training-time and generation-time correction.
Finally
The link below leads to a comprehensive list of research papers for Self-Correcting Large Language Models with Automated Feedback.