The primary focus in training Orca-2, was to create an open-sourced Small Language Model (SLM) which excels at reasoning. This is achieved by decomposing a problem and solving it step-by-step, which adds to observability and explainability.
Data Centric Approach
Even-though the training data for Orca-2 is synthetic and LLM generated, meticulous planning went into designing the training data.
Firstly, focus was given to improving the training signals imbedded in the training data, which enhanced the SLM’s ability to reason.
Secondly, the objective was also to teach the SLM to employ different solution strategies to different tasks; based on the best approach to a specific problem.
These strategies might be different for different tasks, and potentially different from what a LLM might use.
The model should recognise the most effective solution strategy for each task.
Nuanced Data
To create nuanced training data, an LLM is presented with intricate prompts which is designed with the intention to elicit strategic reasoning patterns which should yield more accurate results.
Also, during the training phase, the smaller model is exposed to the task and the subsequent output from the LLM. The output data of the LLM defines how the LLM went about in solving the problem.
But here is the catch, the original prompt is not shown to the SLM. This approach of Prompt Erasure, is a technique which turns Orca-2 into a Cautious Reasoner because it learns not only how to execute specific reasoning steps, but to strategise at a higher level how to approach a particular task.
Rather than naively imitating powerful LLMs, the LLM is used as a reservoir of behaviours from which a judicious selection is made for the approach for the task at hand.
RLHF
Should a process of Reinforcement Learning with Human Feedback be followed, the results, safety and alignment of the SLM should be improved drastically.
Instruction Tuning
Instruction tuning involves learning from input-output pairs where the input is a natural language task description and the output is a demonstration of the desired behaviour.
Instruction tuning has been shown to improve model ability to follow instructions on both seen and unseen tasks, improve the overall quality of the generations and give models enhanced zero-shot and reasoning abilities.
Several studies have adopted instruction tuning to train smaller “student” language models using outputs generated by larger foundational models.
This behaviour cloning has been shown to be very effective in mimicking the style of the teacher model.
The one thing to note is that the SLM does indeed learn new abilities in problem solving, but nothing changes in terms of the knowledge the model holds.
Smaller language models with enhanced reasoning are perhaps best used as reasoning engines over knowledge provided to the model in its context window, or when specialised in narrower domains.
Creating Cautious Reasoners
The following illustrates the process of training a Cautious Reasoning LLM:
- Start with a collection of diverse tasks
- Guided by the performance of Orca, pair specific tasks with specific solutions.
- Decide on a Strategy (e.g. direct-answer, step-by-step, explain-then-answer, etc.)
- Write task-specific system instruction(s) corresponding to the chosen strategy in order to obtain teacher responses for each task.
- Prompt Erasing: At training time, replace the student’s system instruction.
The key idea is that with the absence of the original system instruction which detailed how to approach the task, the student model will be encouraged to learn that underlying strategy as well as the reasoning abilities it entailed.
We call this technique Prompt Erasing as it removes the structure under which the teacher framed its reasoning. Armed with this technique, we present Orca 2, a cautious reasoner.
Practical Reasoning Example
Consider the complex reasoning question below posed to Orca-2…
Solve the following problem by thinking step by step:
John and Mark are in a room with a ball, a basket and a box.
John puts the ball in the box, then leaves for work.
While John is away, Mark puts the ball in the basket, and then leaves for
school. They both come back together later in the day, and they do not know
what happened in the room after each of them left the room.
Where do they think the ball is?
And the detailed and correct response from the SLM:
To solve this problem step by step, let's analyze the events that occurred
while John and Mark were away:
1. John put the ball in the box before leaving for work.
2. While John was away, Mark came into the room and placed the ball in the basket.
3. Both John and Mark left the room without knowing what happened after they
put the ball in its respective location.
4. They both returned to the room together later in the day.
Since neither John nor Mark saw any changes after they put the ball in the
box and the basket, they would naturally assume that the ball is still in the
location they left it in. In this case,
John would think the ball is still in the box, and Mark would think the
ball is still in the basket.
As a result, John thinks the ball is in the box, and Mark thinks the ball is
in the basket.
In Conclusion
The training process for Orca-2 as described in this study, shows how important the process of Data AI is, where data preparation for model training is carefully crafted in terms of the data structure.
But what I find fascinating is that the fine-tuning data is created synthetically by a LLM, to train the SLM.
And not only this, the training of the model is not to imbue the SLM with new knowledge, or adapt the SLM for a specific vertical in terms of industry or enterprise. But rather to train the model to think and reason in a certain way.
Previously published on Medium.
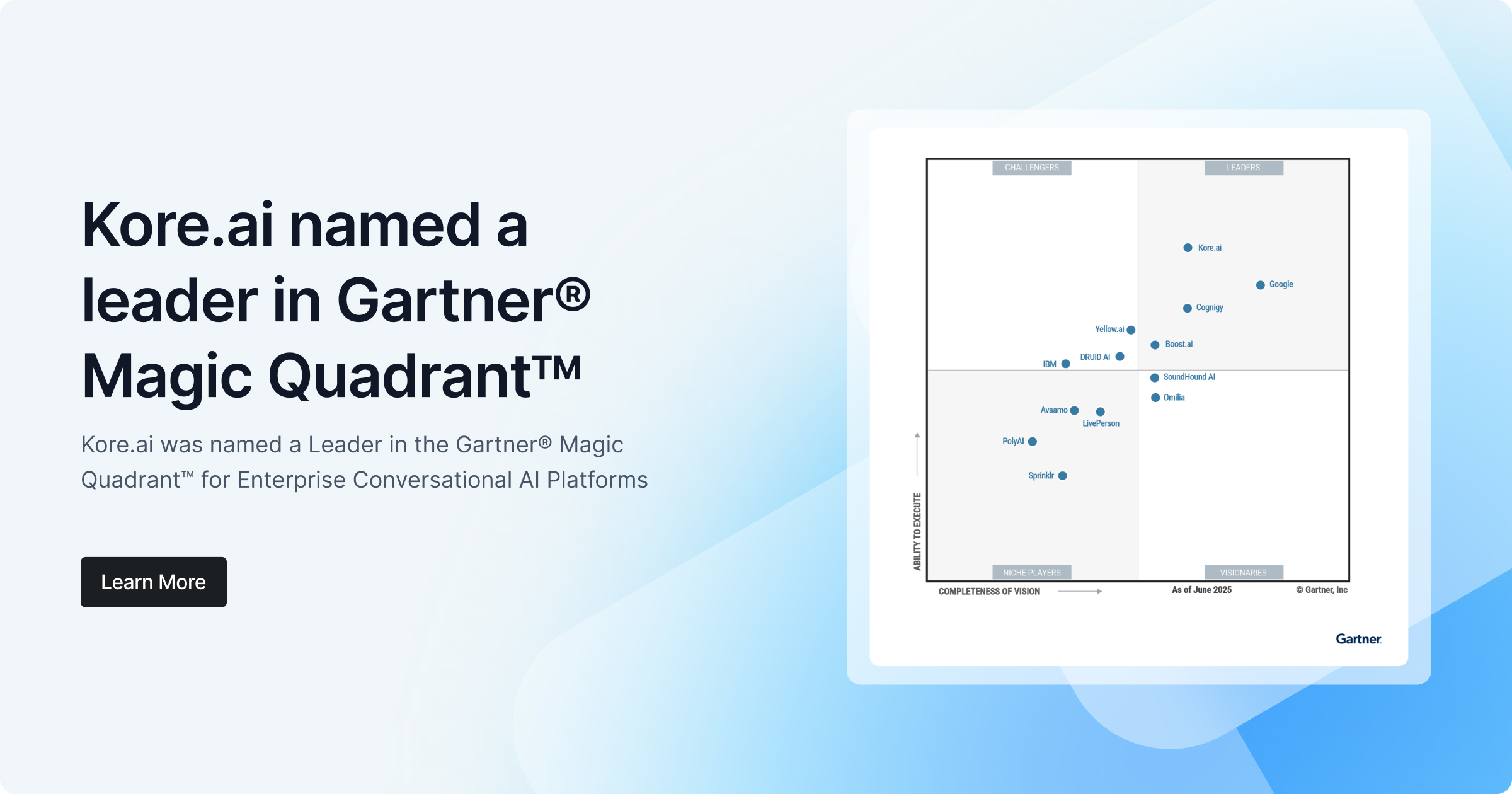
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.