Introduction
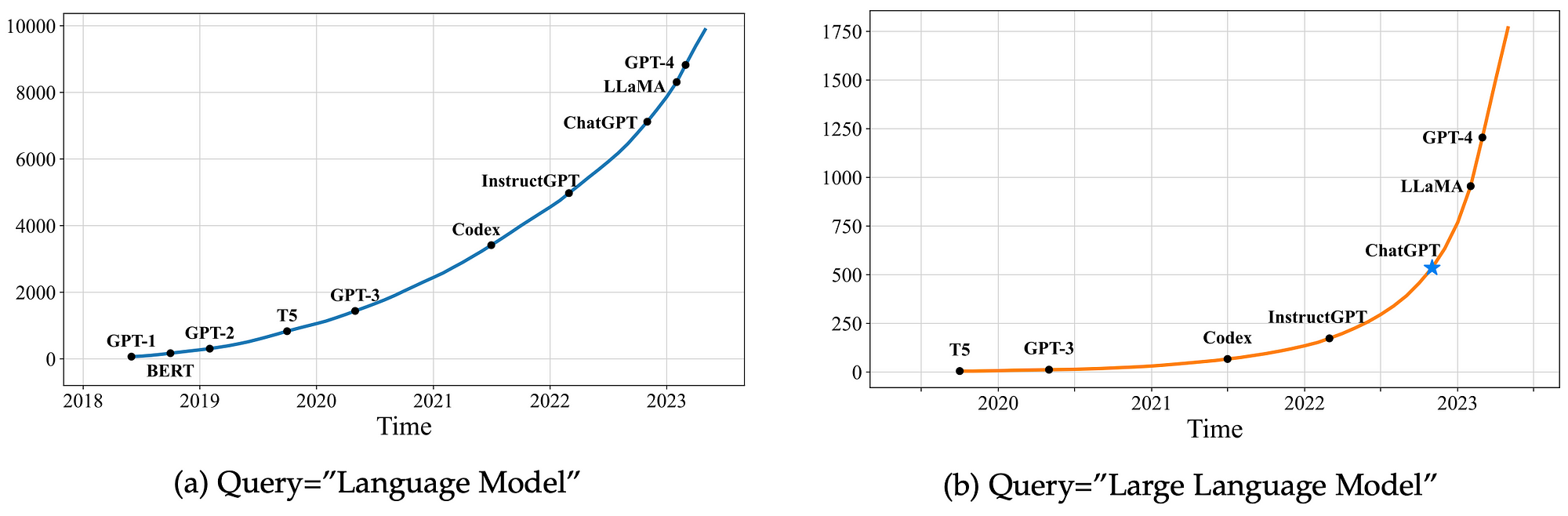
The two graphs below show the cumulative numbers of arXiv papers that contain the key phrases “language model” (since June 2018) and “large language model” (since October 2019), respectively.
The growth since 2019 in papers published related to LLMs is staggering. Obviously commercial products and implementations are lagging behind cutting-edge research.
Considering the recent studies, a number of strengths and opportunities have emerged related to LLMs. But also a number of threats and weaknesses have been identified.
As I discuss later in this article, LLMs are not going away, the potential of LLMs are recognised and the advantages are well established.
The astute entrepreneur see the LLM-related threats and weaknesses not as such, but as opportunities to solve for and serve the market.

SWOT Strengths

Knowledge-Intensive NLP
The best way to describe LLMs is knowledge intensive. The wide base of general knowledge questions which can be answered is one of the reasons ChatGPT has gone mainstream.
Another interesting aspect of the knowledge intensive nature of LLMs is blending.
By blending I refer to the unique capability of LLMs to blend knowledge, for instance the LLM can be instructed, “ (1)explain nuclear physics to a (2)toddler while sounding like (3)Donald Trump.“
Here three input parameters or knowledge types need to be blended seamlessly.
Add to this the ability of LLMs to leverage existing knowledge to make deductions and answer questions the LLM has not explicitly seen before.
One example of this is the ability of LLMs to perform symbolic reasoning.
Human language translation/ Multilingual
LLMs are multilingual and can translate between different languages. In the example below from OpenAI’s Language API referencing the text-davinci-003model, perfect Afrikaans is understood and generated.

The language ability of LLMs are illustrated in them being able to detect intent, extract entities and more.
Natural Language Generation (NLG)
NLG is one of the hallmarks of LLMs, succinct, coherent and consistently good natural human language is generated. In actual fact, hallucination is partly a challenge due to how good the NLG is.
Prompt Engineering
It is curious that prompt engineering is the default interface to LLMs, a method of describing the user-intent to the LLM and providing examples to emulate.
Prompt engineering can be used within a Playground by leveraging, zero, one or few shot learning.
Zero/Few Shot Capabilities refer to LLM ability to yield results with no to very little training data. For instance, one sentence can be supplied to the LLM and the LLM can create any number of synonyms.
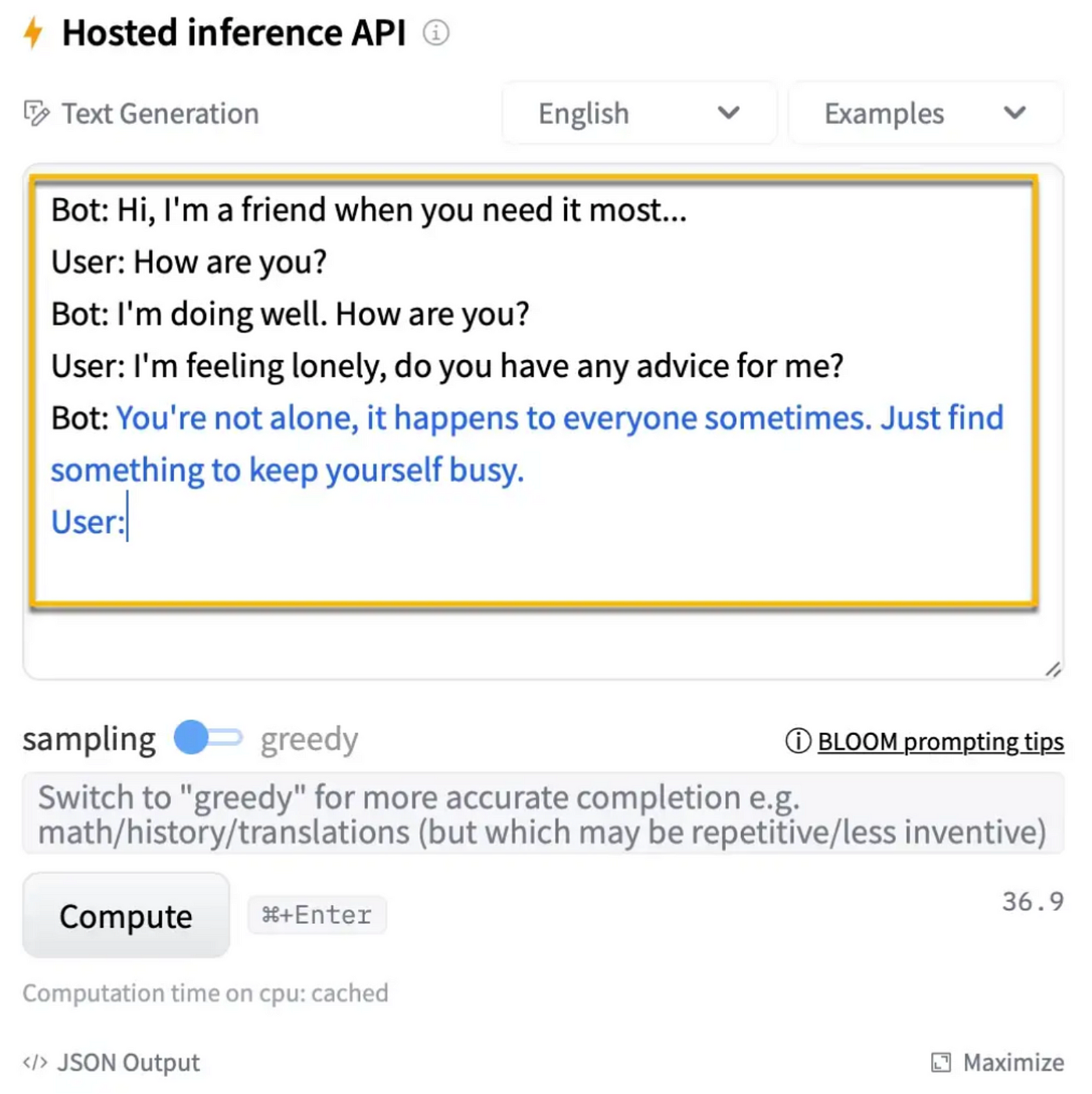
As seen below, dialog turns (Chain-of-Thought Prompting) can be defined via prompt engineering to supply a contextual reference to the LLM at inference.
The example below is from BLOOM via HuggingFace.
Multi-Disciplinary / Modal
In terms of technology, coding etc. The versatility of LLMs is illustrated in their capability in human language and coding.
General search and dialog fall-back.
LLMs can leverage their general knowledge to act as dialog fall-back for out-of-domain questions.
Synthetic training data for chatbots.
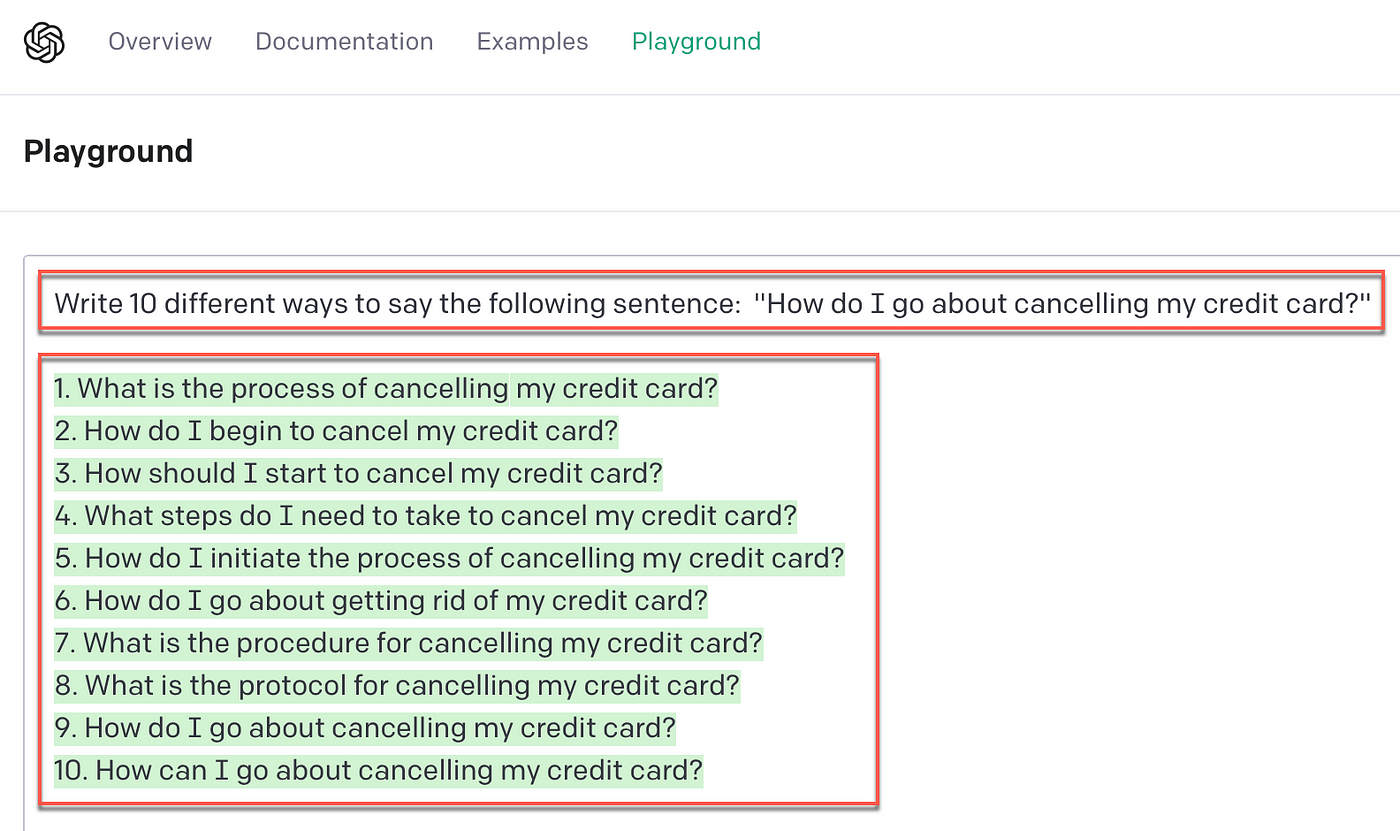
This is currently the most common use of LLMs in chatbot development frameworks. A simple request can generate multiple training phrases for the same intent.
In the example below, a single line allows text-davinci-003 to generate wellformed and cohesive phrases.
Dialog & Context Management
Dialog and context management can be performed via LLMs by including previous dialog turns in the prompt at inference. Granted this increases the size of the prompt, and the input tokens, hence cost. And potentially the already long inference time is increased.
The dialog turns can become very long, especially if previous conversations are included in the conversations. However, most frameworks summarise the conversation history in an effort to preserve conversational context, but introduced data management.
In-Context Learning
A new study argues that Emergent Abilities are not hidden or unpublished model capabilities which are just waiting to be discovered, but rather new approaches of In-Context Learning which are being built.
This study can be considered as a meta-study, acting as an aggregator of numerous other papers.
The hype around Emergent Abilities is understandable, it also elevated this notion of LLMs being virtually unlimited, and that potential game changing, unknown and latent capabilities are just waiting to be discovered.
Knowledge Synthesis
I have spoken about blending and LLMs being able to perform symbolic reasoning. LLMs synthesises a number of technologies and data to receive unstructured input in the form of human conversational data. Perform logic steps on the data, and output unstructured conversational data.
Considering the LLM landscape and how it has evolved, initially there were task specific models; models which focusses on dialog management, or data, coding, translation and more. All of this is being synthesised within single models. And these models are becoming multi-modal in the process.
SWOT Opportunities
Rapid Evolution of Ecosystem
The LLM ecosystem is expanding at a rapid sace; with new categories emerging over a relative short period of time.
Development is not only taking place in the area of LLMs, but also in terms of tools to build. The in-context abilities of LLMs are being recognised, with the advancements in RAG.
Application Build Tools
Application build tools are expanding at a rapid rate; with products choosing to address certain aspects of the market.
Data Delivery
Data delivery can best be described as the process to inject a prompt with highly contextual and relevant data at inference. This real-time process demands the ability to perform semantic search on data. And extracting the most efficient chunk of data in terms of supplying enough context and making the prompt as small as possible.
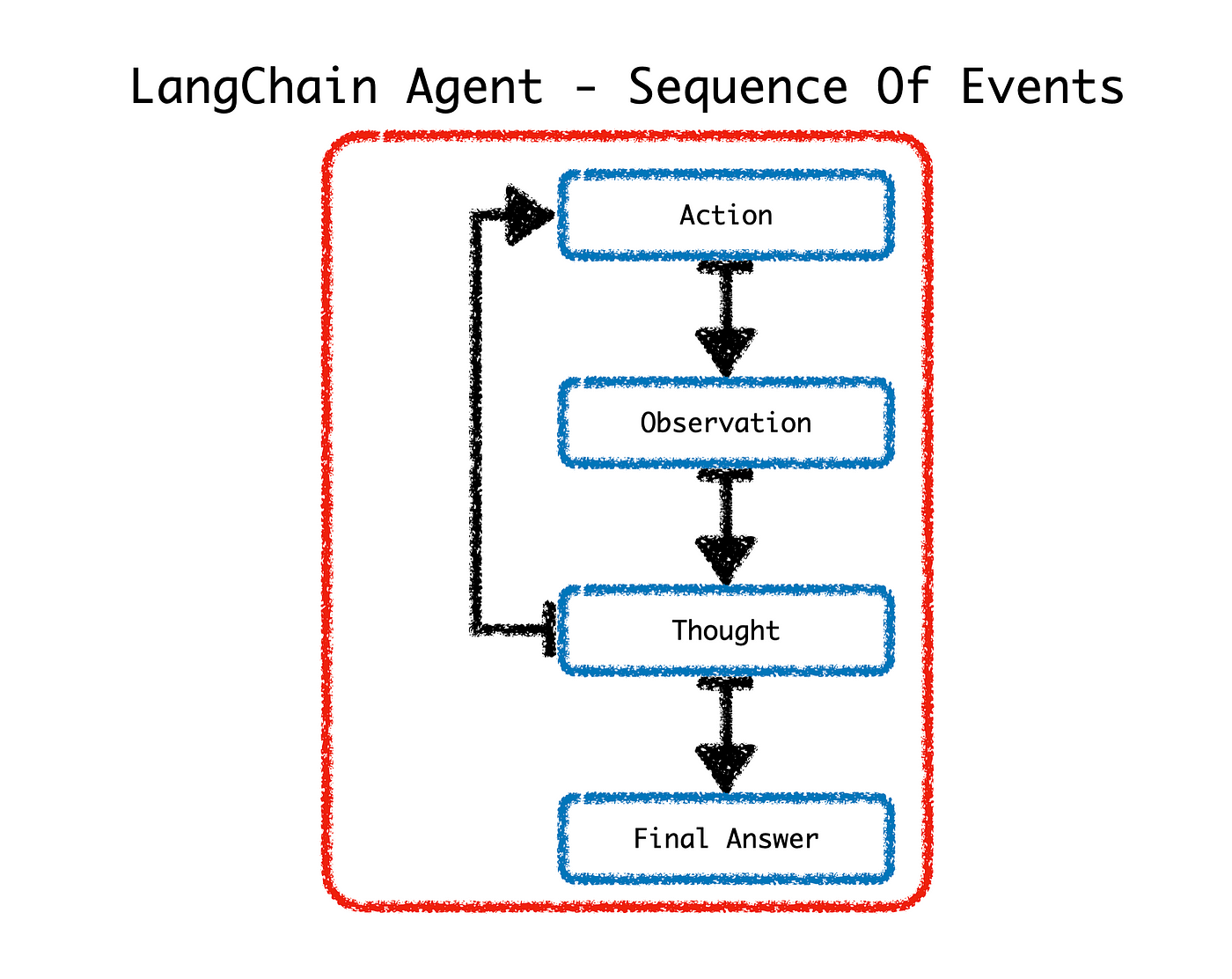
Autonomous Agents
Considering the diagram below, upon receiving a request, Agents leverage LLMs to make a decision on which Action to take. After an Action is completed, the Agent enters the Observation step. From Observation step Agent shares a Thought; if a final answer is not reached, the Agent cycles back to another Action in order to move closer to a Final Answer.
There is a whole array of Actions available to the LangChain Agent.
Open-Source Models
The market opportunity lies with hosting open-source models, which can easily be customised. With cost being only incurred on hosting and services; and no inference token overhead.
Data Centric Approach
Data Design is the next step where the discovered data is transformed into the format required for LLM fine-tuning. The data needs to be structured and formatted in a specific way to serve as optional training data. The design phase compliments the discovery phase, at this state we know what data is important and will have the most significant impact on the users and customers.
Hence data design has two sides, the actual technical formatting of data and also the actual content and semantics of the training data.
Data Development; this step entails the operational side of continuous monitoring and observing of customer behaviour and data performance. Data can be developed by augmenting training data with observed vulnerabilities in the model.
Pipelines / Runnables
Prompt pipelines, also referred to as runnables are emerging as ways to create shareable and modular LLM interfaces.
Data Design Tools
Data centric tooling will increase in importance as a data centric approach is adopted and the need to discover unstructured data increases.
Weakness

- Unstructured Input
The unstructured nature of LLMs remains a challenge together with the non-deterministic nature of LLMs.
- Data Productivity Suites
The Data Productivity suites are lagging behind in the market, and the need for a data centric approach increases.
- Data Discovery
Data Discovery can be seen as a subset of a data productivity suite.
- Inspectability & Observability
One of the pursuits of LangChain is to introduce an element of inspectability and observability. The LLM does not provide this feature, but the interactions with the LLM can be planned and executed in a decomposed fashion.
- Contextual Understanding
LLMs do not magically know context, hence context needs to be established and introduced to the LLM.
- Handling Ambiguity
Ambiguity is still a challenge with LLMs, and an element of disambiguation needs to be introduced.
- Fine Tuning Challenges
Fine-tuning needs to be performed via a no-code, GUI, with a limited amount of data with low token cost.
- Resource Intensive
Currently LLMs are still resource intensive, but of late there has been developments in the field of quantisation and running models on a smaller resource footprint.
Threats

Inference Latency
Inference latency is still a challenge with LLMs taking long to respond to requests. Streaming is one approach to improve the UX.
Inference Cost
In this article I explain OpenAI token usage for model input, output & fine-tuning. And how to convert text into tokens to calculate token-use cost.
Security & Privacy Concerns
LLMs raise significant privacy and security concerns as their deployment in various applications necessitates handling sensitive user data.
The fine line between providing personalized responses and preserving user privacy becomes challenging, requiring robust measures to prevent inadvertent data exposure. Additionally, the susceptibility of these models to adversarial attacks underscores the need for rigorous security protocols to safeguard against potential misuse or malicious exploitation.
Hallucination
I like to describe ungrounded hallucination as LLM generated responses, which are succinct, highly plausible and believable, but factually incorrect.
Alignment
Alignment refers to ensuring models behave in accordance to what the intention of the prompt was. This comes down to the accuracy of prompt engineering.
Prompts are in essence a body of text where the user defines, or rather describes, their intent. And by implication the user describes the intended outcome in the prompt.
Model Drift
A recent study coined the term LLM Drift. LLM Drift is definite changes in LLM responses and behaviour, over a relatively short period of time. Read more here.
Prompt Drift
The notion to create workflows (chains) which leverage Large Language Models (LLMs) are necessary and needed. But there are a few considerations, one of which is Prompt Drift.