Comparing different LLM knowledge injection methods…Fine-Tuning or RAG? The short answer is, it depends…
There are a number of considerations to take into account:
- Cost: will the money spent on data design and development for fine-tuning yield the required benefits? Think of the cost in terms of people, technology and process.
- Available Data: what propriety data is available, and in what format? What makes RAG so attractive is that it is not as opaque as fine-tuning. And it is technically easier to implement.
- Available Models: what models are available and selected for use? Models have varying performance with regards to fine-tuning and RAG. There are models where the potential performance enhancement from fine-tuning cannot be neglected.
- Model Agnostic: organisations want to run LLMs and SLMs locally to circumnavigate impediments like inference latency, inference cost, rate limits, data privacy & security etc. Some open-source models perform better when fine-tuning and RAG are combined. And as seen below, with other models there is a deprecation, and a RAG-only approach yields the best results.
- Fine-Tuning Data: It needs to be noted that this study from Microsoft made use of unsupervised fine-tuning, which means the data was not annotated. Fine-tuned models could benefit from additional alignment through supervised fine-tuning.
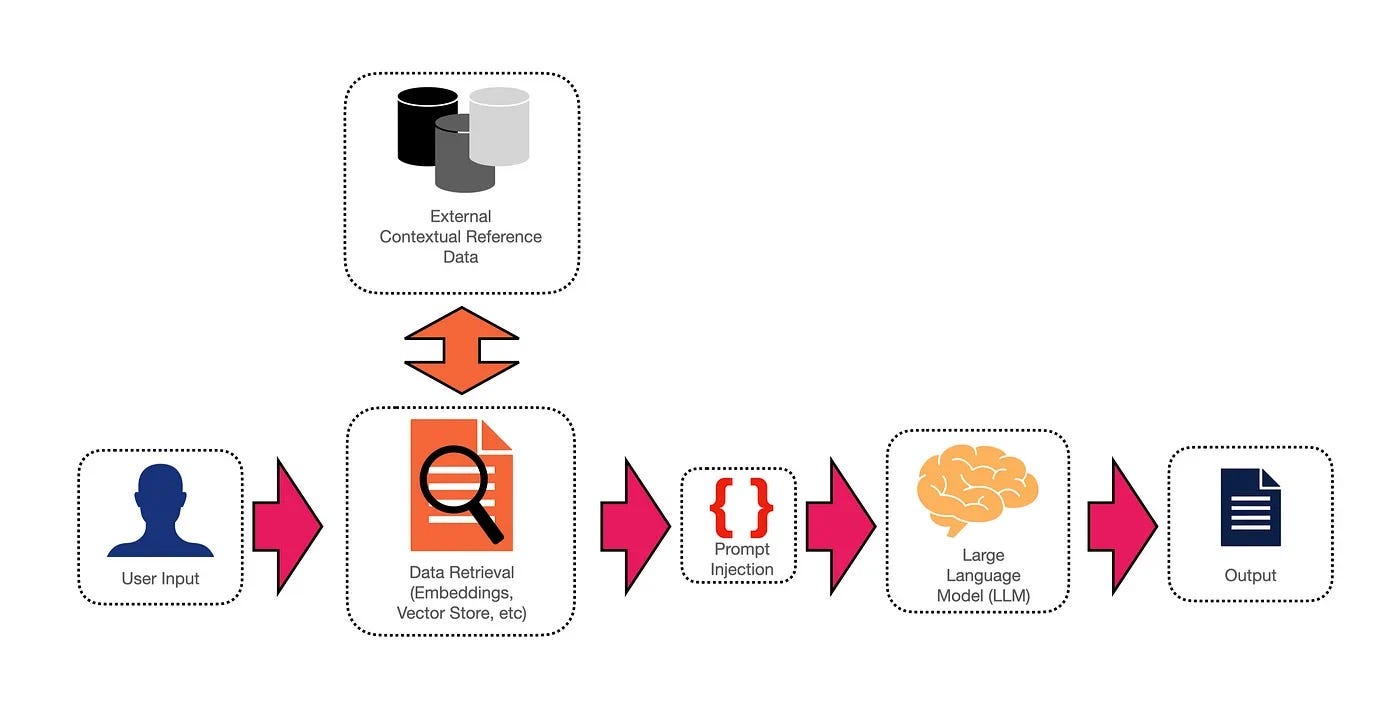
Basic RAG architecture
- Model Independence: Fine-tuning demands investing time and money into a single model. RAG allows for model independence to a large degree, because the technology sits outside the ambit of the LLM.
- Ongoing Maintenance: Due to the non-opaque nature of RAG, ongoing updates and data maintenance are easier.
- Observability & Inspectability: User input can easily be paired with retrieved contextual reference data and the LLM’s generated response.
Supervised & Unsupervised Fine-Tuning
It needs to be noted that this study from Microsoft made use of unsupervised fine-tuning, which means the data was not annotated.
The Results
The results from the current events tasks clearly demonstrate a significant advantage for RAG over fine-tuning. While fine-tuning did enhance results compared to the base model in many instances, it fell short of competing with the effectiveness of the RAG approach.
Several factors likely contribute to this discrepancy.
Firstly, RAG not only enriches the model with knowledge but also incorporates context that is pertinent to the question, a capability lacking in fine-tuning.
Secondly, fine-tuning may adversely affect other aspects of the model due to a phenomenon known as catastrophic forgetting.
Thirdly, it’s conceivable that unsupervised fine-tuned models could benefit from additional alignment through supervised fine-tuning, as illustrated by the markedly improved performance of Orca2 over the base Llama2.
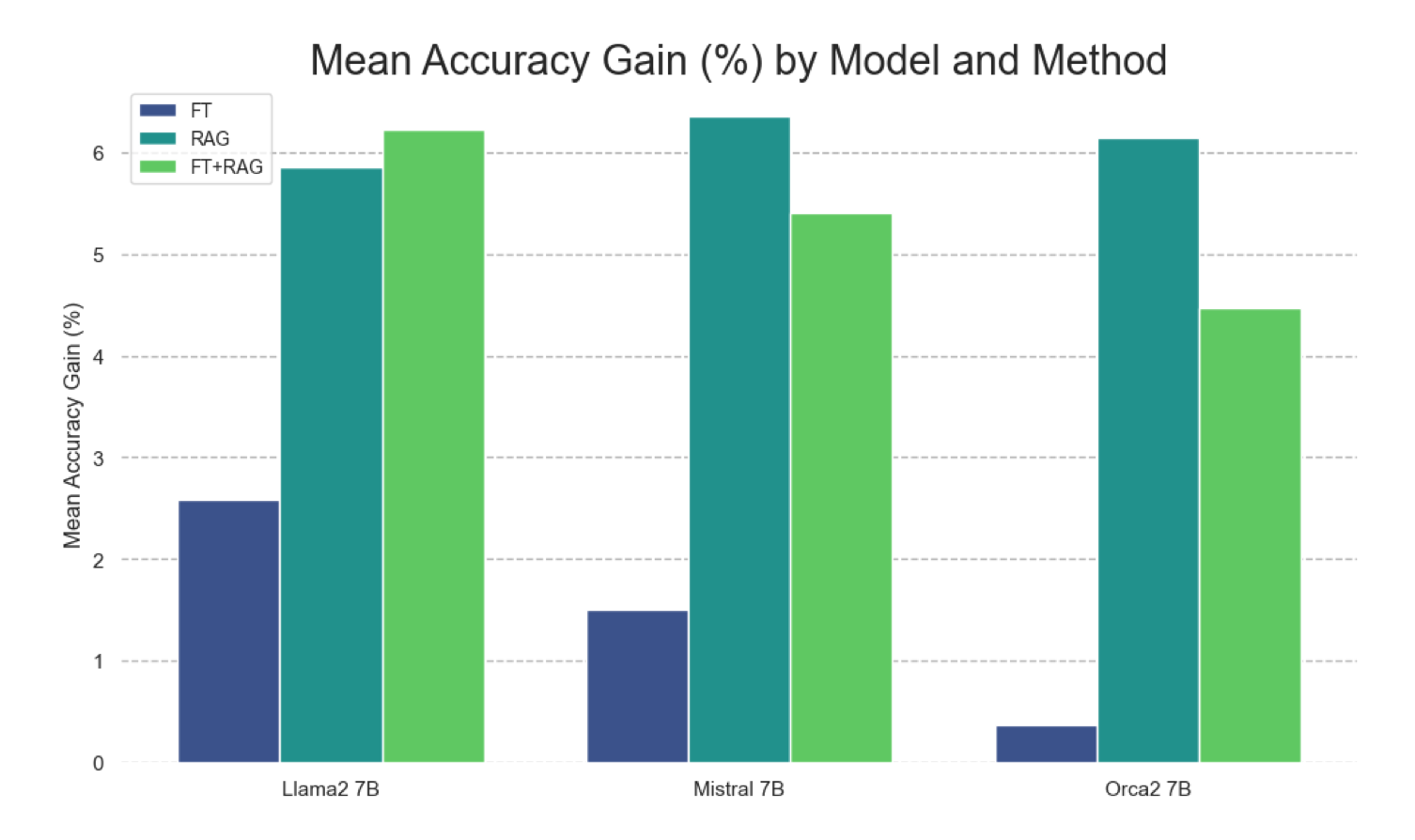
Considering the graph above, the relative accuracy gains for each knowledge-injection method is shown…what is evident is how much it differs between models.
What is also interesting is how RAG performs, and Fine-Tuning combined with RAG does not always outperform a single approach of RAG or Fine-Tuning.
In Closing
Some aspects of this study warrant further research. For example, for fine-tuning the study focussed on unsupervised training as the primary fine-tuning method, as opposed to instruction-tuning or supervised fine-tuning.
Doing the research over other LLMs can also yield interesting results.
Find the study here.










