Fine-Tune your LLM To fully utilise the available context window.
Something I find intriguing considering recent studies, is the fact that certain fine-tuning and gradient techniques don’t primarily aim to infuse the language model with domain-specific data.
Instead, their primary goal is to alter the model’s behaviour and instruct it in specific tasks through the design and structure of the fine-tuning data.
These tasks encompass functionalities like reasoning, self-correction and handling large context better. IN2 is yet another example of this approach.
The Problem
Currently a number of large language models (LLMs) can receive as input lengthy text. Something we refer to as the context window, or large context window.
However, LLMs still struggle to fully utilise information within the long context, known as the lost-in-the-middle challenge. This is the phenomenon where emphasis is being placed by the LLM on information at the beginning and the end of the corpus of data submitted. While neglecting the middle portion, when a questions is asked over the body of data.
The root cause of lost-in-the-middle stems from the unintentional bias hidden in the general training data.
The Solution
A recent study has the view that insufficient explicit supervision during the long-context training is to blame for this phenomenon.
Explicit supervision should explicitly emphasise the fact that any position in a long context can hold crucial information.
Enter INformation-INtensive (IN2) Training
IN2 is a purely data-driven solution to overcome lost-in-the-middle.
IN2 training leverages a synthesised long-context question-answer dataset, where the answer requires two elements:
- Fine-Grained information awareness on a short segment, within a synthesised long context.
- The integration and reasoning of information from two or more short segments.
In auto-regressive pre-training, predicting the next token is often more influenced by nearby tokens rather than distant ones.
Similarly, in supervised fine-tuning, system messages that strongly impact response generation are usually placed at the beginning of the context. This can create a bias, suggesting that important information is always found at the beginning or end of the context.
INformation-INtensive (IN2) has as its focus, the training of the LLM to explicitly teach the model that crucial information can be intensively present throughout the context, not just at the beginning and end.
IN2 is a purely data driven solution.
The How Of IN2
The long context, spanning from 4K to 32K tokens, is compiled from numerous short segments of around 128 tokens each.
Question-answer (QA) pairs inquire about information located within one or more segments, which are randomly positioned within the long context.
Two types of questions are generated:
- One demands detailed knowledge about a single short segment,
- While the other necessitates integrating and reasoning about information from multiple segments.
These QA pairs are produced by instructing GPT-4-Turbo (OpenAI, 2023b) with specific guidelines and the raw segments.
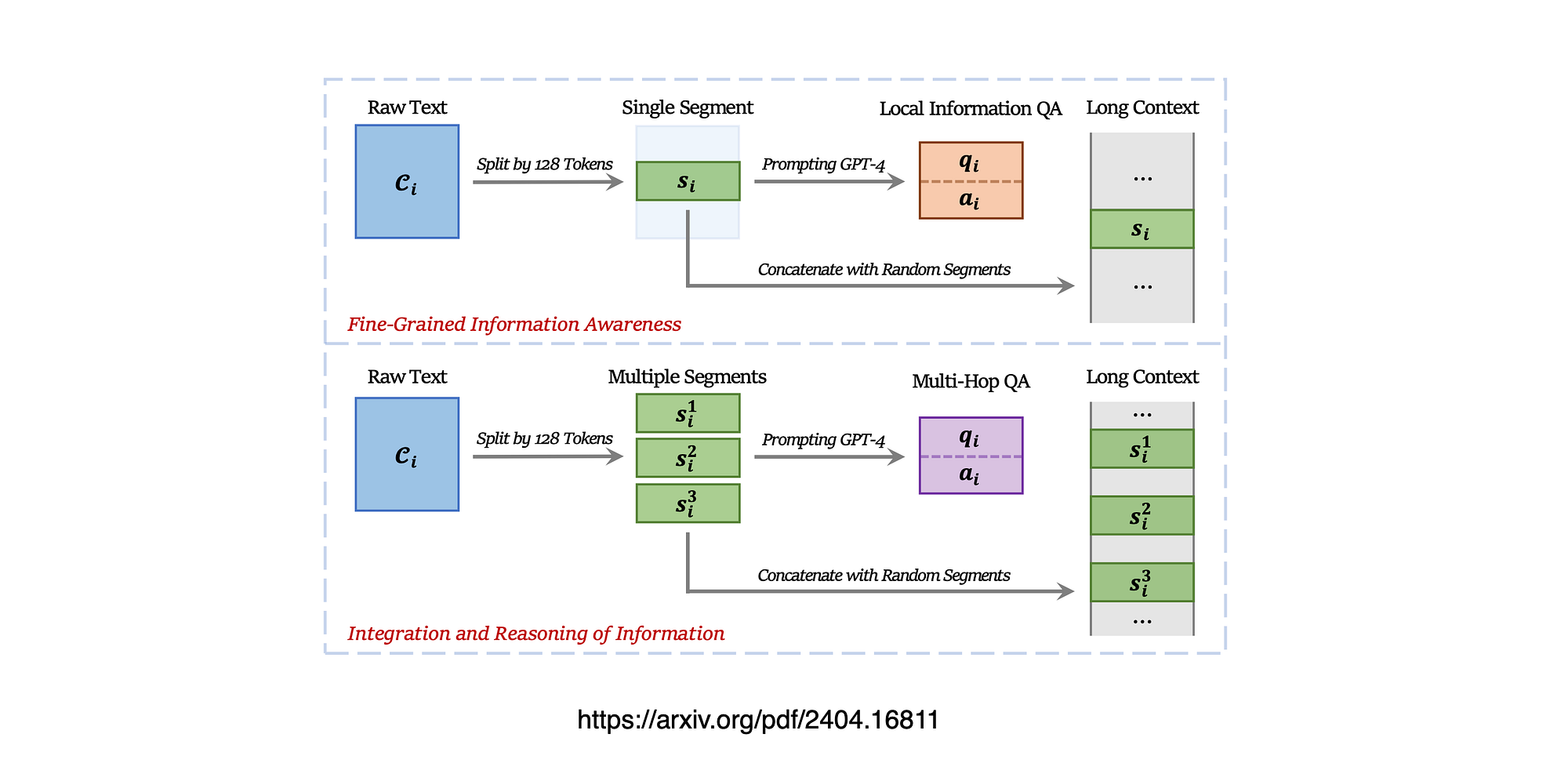
Considering the image above, flow for creating training data:
Top: Enhancing the fine-grained information awareness
Bottom: Integration & Reasoning Of Information
Fine-Grained Information Awareness
The minimum information unit of context was considered as a 128-token segment.
Below are three examples from the study, illustrating how the fine-grained information awareness data is designed.

Notice the segment, the question with the appropriate answer within the context.

And below a longer example in terms of the segment and answer all within context.

Integration & Reasoning of Information
Beyond utilising each single segment, the study considered how to generate question-answer pairs for information contained in two or more segments.

Below a shorter example in terms of the answer.

And yet another variation…

Prompts For Data Generation and Training
The templates used below…

Finally
This study introduces IN2 training to address the lost-in-the-middle challenge and demonstrates substantial enhancements in both probing tasks and real-world long-context tasks without sacrificing performance in short-context scenarios.